V této kapitole si ukážeme, že některé úlohy vyhledávání v databázích můžeme interpretovat a řešit geometricky, pokud se na databáze budeme dívat jako na množiny bodů ve vícerozměrných prostorech. Jestliže každá položka v databázi obsahuje $d$ různých údajů, můžeme tyto údaje chápat jako souřadnice v prostoru $\mathbb R^d$ a databázi si můžeme představit jako množinu bodů v $\mathbb R^d$.
Často se můžeme setkat s úlohou najít v databázi ty položky, jejichž jednotlivé údaje se pohybují v zadaném rozmezí. To vede na geometrickou úlohu ortogonálního vyhledávání.
Formulace obecné úlohy ortogonálního vyhledávání v $\mathbb R^d$
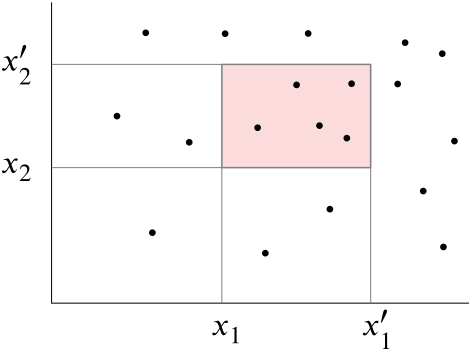
V $\mathbb R^d$ je dána množina bodů $P$. Úloha ortogonálního vyhledávání spočívá v nalezení vhodné vyhledávací struktury vytvořené právě pro tuto množinu, která umožní pro
každé zadání intervalů $[x_1,x_1']$, $[x_2,x_2']$, $\dots$, $[x_d,x_d']$ najít rychle všechny body množiny $P$, které leží v „kvádru“
My se budeme zabývat dvěma způsoby, jak takovou úlohu řešit. Příslušné vyhledávací struktury se nazývají kd-trees a range trees. V prvém případě budeme používat českého překladu kd-stromy, v druhém zůstaneme u anglického názvu. Začneme dimenzí $1$, v níž obě metody splývají.
Vyhledávání v dimenzi jedna
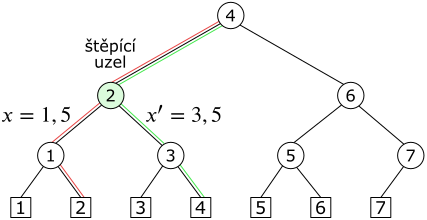
Nechť $P=\{p_1,p_2,\dots, p_n\}$ je množina reálných čísel. Pro tuto množinu můžeme sestrojit vyvážený binární strom $\mathcal T$, v jehož listech jsou uspořádany podle velikosti prvky této množiny. Dostaneme zadána čísla $x$ a $x'$, $x\leq x'$ a hledáme prvky množiny $P$, které leží v intervalu $[x,x']$. Ve stromu $\mathcal T$ ponese každý uzel hodnotu největšího listu svého pravého podstromu. Potom každé číslo $x$ určuje ve stromu cestu od kořene k nějakému listu, která je zadána pravidlem, že z daného uzlu jdeme vlevo, pokud je $x$ menší nebo rovno hodnotě v tomto uzlu, a jdeme vpravo v opačném případě.
Zadaná čísla $x$ a $x'$ určují dvě cesty, které mají společnou část. Poslední uzel společné části nazýváme štěpící uzel, anglicky split node.
Obrázek 7.2 Štěpící uzel pro $x=1,5$ a $x'=3,5$. Cesta pro $x$ je vyznačena červeně, cesta pro $x'$ zeleně.
Označíme-li nějaký uzel stromu $\mathcal T$ jako $\nu$, pak jeho levý následník bude
$\operatorname{lc}(\nu)$ a pravý následník $\operatorname{rc}(\nu)$. Algoritmus pro nalezení štěpícího uzlu má následující jednoduchý pseudokód:
FindSplitNode$(\mathcal T, x, x')$
Input. A tree $\mathcal T$ and two values $x$ and $x'$ with $x\leqslant x'$.
Output. The node $v$ where the paths to $x$ and $x'$ split, or the leaf where both paths end.
$v\leftarrow root(\mathcal T)$
while $v$ is not a leaf and $(x'\leqslant x_v$ or $x\gt x_v)$
do if $x'\leqslant x_v$
then $v\leftarrow lc(v)$
else $v\leftarrow rc(v)$
return $v$
Algoritmus pro nalezení bodů ležících v intervalu $[x,x']$ najde prvně štěpící bod a pak pokračuje ve vyhledání pozice čísel $x$ a $x'$ v daném uspořádání množiny $P$ pomocí vyváženého binárního stromu $\mathcal T$.
then Check if the point stored at $v_{\text{split}}$ must be reported.
else (* Follow the path to $x$ and report the points in subtrees right of the path. *)
$v\leftarrow lc(v_{\text{split}})$
while $v$ is not a leaf
do if $x\leqslant x_v$
thenReportSubtree(rc($v$))
$v\leftarrow lc(v)$
else $v\leftarrow rc(v)$
Check if the point stored at the leaf $v$ must be reported.
Similarly, follow the path to $x'$, report the points in subtrees left of the path, and check if the point stored at the leaf where the path ends must be reported.
Jestliže v intervalu $[x,x']$ leží $k$ čísel z množiny $P$, čas potřebný pro jejich vypsání je
$O(\log n+k)$.
kd-stromy v dimenzi 2
Nechť $P=\{p_1,p_2,\dots, p_n\}$ je množina bodů v rovině $\mathbb R^2$. Pro geometrickou názornost a zjednodušení výkladu budeme předpokládat, že žádné dva z nich nemají stejnou $x$-ovou ani $y$-ovou souřadnici. Časem si ukážeme, jak tento omezující předpoklad odstranit.
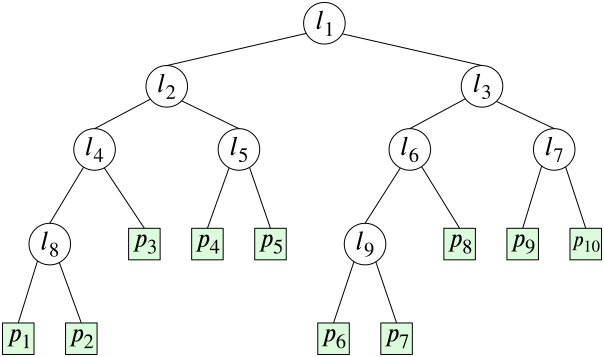
kd-strom pro množinu $P$ bude mít geometrickou podobu rozdělení roviny pomocí vertikálních a horizontálních přímek, polopřímek a úseček na části, z nichž každá bude obsahovat právě jeden bod množiny $P$. Toto geometrické dělení popíšeme pomocí vyváženého binárního stromu, který se nazývá kd-stromem.
Nejdříve najdeme bod množiny $P$ s vlastností, že vertikální přímka $l_1$ jím vedená rozdělí
množinu $P$ na dvě části $P_1$ a $P_2$ takové, že počet prvků množiny $P_1$ je stejný nebo o jeden větší než počet prvků množiny $P_2$. Do množiny $P_2$ zařadíme body ležící vpravo od přímky $l_1$, ostatní body leží v množině $P_1$. To znamená, že $x$-ová souřadnice bodu, kterým prochází přímka $l_1$ bude mediánem $x$-ových souřadnic bodů množiny $P$. V kd-stromu bude tento geometrický krok odpovídat výběru kořene, v něm budeme uchovávat vertikální přímku $l_1$ společně s její $x$-ovou souřadnicí. Cesta z tohoto kořene vlevo značí přechod k množině $P_1$, cesta vpravo přechod k $P_2$.
V dalším kroku rozdělíme analogicky množiny $P_1$ a $P_2$ horizontálními přímkami
$l_2$ a $l_3$ na dvě množiny, z nichž ta dolní obsahující i bod na dělící horizontální polopřímce má počet bodů stejný nebo o jeden větší než množina horní. V kd-stromu budou přímky $l_2$ a $l_3$ odpovídat levému a pravému následníkovi uzlu $l_1$.
Získané množiny – nyní jsou již čtyři – rozdělíme opět vertikálními přímkami na množiny, jejichž počty prvků se liší maximálně o jeden. Tento postup opakujeme tak dlouho, dokud v získaných množinách není jeden bod. Celý postup je na příkladu zachycen v následující animaci.
Po skončení dostáváme vyvážený binární strom, kde v uzlech na sudé úrovni uchováváme $x$-ovou souřadnici dělící vertikální přímky a v uzlech na liché úrovni uchováváme $y$-ovou souřadnici horizontální dělící přímky.
Obrázek 7.3 kd-strom pro množinu $P$ z animace.
kd-strom zkonstruujeme pomocí rekurzivní procedury popsané následujícím pseudokódem:
AlgorithmBuildKdTree$(P, depth)$
Input. A set of points $P$ and the current depth $depth$.
Output. The root of a kd-tree storing $P$.
if $P$ contains only one point
then return a leaf storing this point
else if $depth$ is even
then Split $P$ into two subsets with a vertical line $\ell$ through the median $x$-coordinate of the points in $P$. Let $P_1$ be the set of points to the left of $\ell$ or on $\ell$, and let $P_2$ be the set of points to the right of $\ell$.
else Split $P$ into two subsets with a horizontal line $\ell$ through the median $y$-coordinate of the points in $P$. Let $P_1$ be the set of points below $\ell$ or on $\ell$, and let $P_2$ be the set of points above $\ell$.
Create a node $v$ storing $\ell$, make $v_{\text{left}}$ the child of $v$, and make $v_{\text{right}}$ the right child of $v$.
return $v$
Lemma 7.1
kd-strom pro množinu $n$ bodů v rovině vyžaduje paměť velikosti $O(n)$ a může být zkonstruován v čase $O(n\log n)$.
Důkaz
Paměť potřebná pro vyvážený binární strom s $n$ listy je $O(n)$. Medián množiny $n$ čísel lze nalézt v čase $O(n)$. Nicméně takové algoritmy jsou poměrně komplikované. Proto je lepší předuspořádat body množiny $P$ podle $x$-ové a $y$-ové souřadnice, což bude trvat čas $O(n\log n)$. Pak nalezení mediánu v nějaké podmnožině bude lineární v počtu prvků této podmnožiny. Tedy z uvedeného algoritmu plyne pro časovou náročnost $T(n)$ rekurentní formule
$$T(1)=O(1),\quad T(n)=O(n)+2T(n),$$
která má řešení $O(n\log n)$.
\(\Box\)
Vyhledávání pomocí kd-stromu
K popisu vyhledávacího algoritmu potřebujeme pojem regionu uzlu $\nu$.
Nechť cesta od kořene k uzlu $\nu$ v kd-stromu je tvořena uzly $\nu_1$, $\nu_2$, $\dots$,
$\nu_k$, $\nu$. Nechť s uzlem $\nu_i$ je svázána přímka $l_i$. Potom region uzlu $\nu$ je průnik příslušných polorovin určených přímkami $l_1$, $l_2$ až $l_k$. Přitom po cestě vlevo
z uzlu sudé úrovně bereme uzavřenou levou polorovinu, po cestě vpravo otevřenou pravou polorovinu. Po cestě z uzlu liché úrovně vlevo bereme v průniku dolní uzavřenou polorovinu, po cestě vpravo horní otevřenou polorovinu.
Obrázek 7.4 Region uzlu $\nu$.
Jestliže je s uzlem $\nu$ svázána přímka $l$, pak lze definici regionu napsat rekurentně takto:
kde $\operatorname{left(l)}$ a $\operatorname{right(l)}$ jsou poloroviny popsané v předchozím odstavci.
Mějme nyní v rovině zadán pravoúhelník $R=[x,x']\times [y,y']$. Chceme pomocí kd-stromu najít body množiny $P$, které v něm leží. Pro region daného uzlu mohou nastat tyto možnosti:
Leží celý v $R$. Pak v $R$ leží všechny body množiny $P$ z tohoto regionu.
Má s pravoúhelníkem $R$ prázdný průnik. Pak v $R$ neleží žádný bod množiny $P$ z tohoto regionu.
Má neprázdný průnik s $R$, ale neleží v něm celý. V tomto případě musíme začít zkoumat regiony příslušné levému a pravému následníku daného uzlu.
Následující obrázek zachycuje regiony všech tří typů.
Obrázek 7.5 Regiony typu (1) jsou zelené, typu (2) modré a typu (3) bílé.
Výše uvedený princip je realizován v následujícím pseudokódu:
AlgorithmSearchKdTree$(v, R)$
Input. The root of (a subtree of) a kd-tree, and a range $R$.
Output. All points at leaves below $v$ that lie in the range.
if $v$ is a leaf
then Report the point stored at $v$ if it lies in $R$.
else if $region(lc(v))$ is fully contained in $R$
thenReportSubtree$(lc(v))$
else if $region(lc(v))$ intersects $R$
thenSearchKdTree$(lc(v), R)$
if $region(rc(v))$ is fully contained in $R$
thenReportSubtree$(rc(v))$
else if $region(rc(v))$ intersects $R$
thenSearchKdTree$(rc(v), R)$
Bez důkazu uvedeme následující tvrzení o časové náročnosti vyhledávání podle kd-stromu.
Lemma 7.2
Nechť množina $P$ v rovině má $n$ bodů a nechť $k$ jich leží v pravoúhelníku R. Pak časová náročnost pro jejich nalezení pomocí kd-stromu je
$$O(\sqrt{n}+k).$$
Vše jsme prozatím prováděli za předpokladu, že žádné dva body množiny $P$ nemají stejnou souřadnici $x$ ani $y$. Nyní si ukážeme, jak lze tento nepříjemný předpoklad odstranit. Místo čísel budeme na místě souřadnic uvažovat dvojice čísel uspořádané lexikograficky. Jestliže bod má souřadnice $(x,y)$, pak jeho „nové“ souřadnice definujeme jako dvojice
$$\{(x,y),(y,x)\}.$$
Potom každé dva různé body v rovině mají odlišnou první i druhou novou souřadnici.
Můžeme proto použít výše uvedené algoritmy, kde klasické souřadnice nahradíme novými souřadnicemi a s těmi počítáme v lexikografickém uspořádání.
Range trees
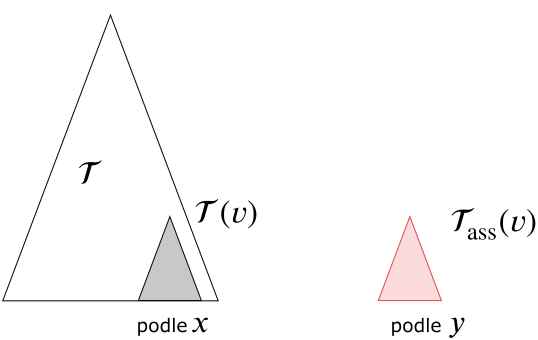
Nyní popíšeme druhou vyhledávací strukturu, opět za zjednodušujícího předpokladu, že žádné dva body z množiny $P$ nemají stejnou $x$-ovou ani $y$-ovou souřadnici. Vyhledávací struktura pro množinu $P$ se skládá z binárního vyváženého stromu $\mathcal T$, který má v listech body množiny $P$ uspořádané podle $x$-ové souřadnice. Každý uzel $\nu$ v $\mathcal T$ určuje podstrom $\mathcal T(\nu)$, jehož je kořenem. Ke každému takovému podstromu vytvoříme tzv. asociovaný podstrom $\mathcal T_{\rm ass}(\nu)$, který má v listech stejné body jako podstrom $\mathcal T(\nu)$, ale uspořádané podle souřadnice $y$.
Obrázek 7.6 Asociovaný podstrom.
Strom $\mathcal T$ společně se systémem asociovaných podstromů $\mathcal T_{\rm ass}
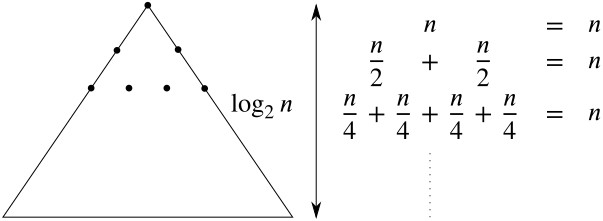
(\nu)$ pro každý uzel $\nu$ z $\mathcal T$ nazýváme range tree. Jestliže množina $P$ obsahuje $n$ bodů, tak asociovaný podstrom pro uzel $\nu$, do kterého se ve stromu $\mathcal T$ dostaneme z kořene po $i$ krocích, vyžaduje paměť úměrnou počtu listů, tj.
$$O\left(\frac{n}{2^i}\right).$$
Takových uzlů je ve stromě $\mathcal T$ celkem $2^i$, proto k nim příslušné podstromy
vyžadují paměť $O(n)$. Vzhledem k tomu, že $i$ nabývá hodnot $0,1,2,\dots,\log_2n-1$, je paměťová náročnost range tree pro $n$-prvkovou množinu
$$O(n\log n).$$
Tedy je vyšší než u kd-stromu, zato vyhledávání pomocí range tree bude rychlejší.
Obrázek 7.7 Paměťová náročnost range tree je $O(n\log n)$.
Konstrukce range tree je popsána následujícím pseudokódem:
AlgorithmBuild2DRangeTree$(P)$
Input. A set $P$ of points in the plane.
Output. The root of a 2-dimensional range tree.
Construct the associated structure: Build a binary search tree $\mathcal{T}_{\text{assoc}}$ on the set $P_y$ of $y$-coordinates of the points in $P$. Store at the leaves of $\mathcal{T}_{\text{assoc}}$ not just the $y$-coordinate of the points in $P_y$, but the points themselves.
if $P$ contains only one point
then Create a leaf $v$ storing this point, and make $\mathcal{T}_{\text{assoc}}$ the associated structure of $v$.
else Split $P$ into two subsets; one subset $P_{\text{left}}$ contains the points with $x$-coordinate less than or equal to $x_{\text{mid}}$, the median $x$-coordinate, and the other subset $P_{\text{right}}$ contains the points with $x$-coordinate larger than $x_{\text{mid}}$.
Create a node $v$ storing $x_{\text{mid}}$, make $v_{\text{left}}$ the left child of $v$, make $v_{\text{right}}$ the right child of $v$, and make $\mathcal{T}_{\text{assoc}}$ the associated structure of $v$.
return $v$
Vyhledávání pomocí range-tree
Je založeno na jednodimenzionálním vyhledávání, nejdřív podle souřadnice $x$, potom podle souřadnice $y$. Mějme zadány intervaly $[x,x']$ a $[y,y']$. Začneme s vyhledáváním
ve stromě $\mathcal T$ podle $x$-ové souřadnice. Pro interval $[x,x']$ v něm prvně
najdeme štěpící uzel. Za ním se cesty pro $x$ a $x'$ rozcházejí.
Jestliže cesta pro $x$ vede z uzlu $\nu$ vlevo, tak $x$-ové souřadnice všech listů podstromu pravého následníka $\operatorname{rc}(\nu)$ leží v intervalu $[x,x']$ a stačí tedy zjistit, které z $y$-ových souřadnic leží v intervalu $[y,y']$. To provedeme jednodimenzionálním vyhledáváním ve stromě $\mathcal T_{\rm ass}(\operatorname{rc}(\nu))$. Jestliže cesta pro $x$ zamíří z uzlu $\nu$ vpravo, tak nemůžeme nic podobného tvrdit a musíme hledat další cestu pro $x$ z pravého následníka uzlu $\nu$.
Při vyhledávání cesty pro $x'$ za štěpícím uzlem postupujeme analogicky. Jde-li cesta
vpravo, $x$-ové souřadnice všech listů levého podstromu leží v $[x,x']$ a proto ve stromu
$\mathcal T _{\rm ass}(\operatorname{lc}(\nu))$ vyhledáme, které z listů mají $y$-ovou souřadnici v $[y,y']$. Vyhledávací algoritmus je zachycen v následujícím pseudokódu:
Check if the point stored at $v$ must be reported.
Similarly, follow the path from $rc(v_{\text{split}})$ to $x'$, call 1DRangeQuery with the range $\left[y:y'\right]$ on the associated structures of subtrees left of the path, and check if the point stored at the leaf where the path ends must be reported.
Nyní ukážeme, že časová náročnost vyhledávání pomocí range tree je příznivější než časová náročnost vyhledávání pomocí kd-stromu.
Lemma 7.3
Nechť množina $P$ v rovině má $n$ bodů a nechť $k$ jich leží v pravoúhelníku R. Pak časová náročnost pro jejich nalezení pomocí range tree je
$$O(\log^2n+k).$$
Důkaz
Vyhledávání v asociovaném stromě levého nebo pravého následníka uzlu $\nu$ s $n_\nu$ listy, kde $k_\nu$ z nich leží v pravoúhelníku $R$, trvá čas
$$O(\log n_\nu+k_\nu).$$
Celkový čas potřebný k vyhledání všech bodů množiny $P$, které leží v pravoúhelníku
$[x,x']\times[y,y']$ je tedy
$$O\left(\sum (\log n_\nu+k_\nu)\right),$$
kde součet bereme přes všechny uzly, kterými prochází cesta pro $x$ a $x'$.
Obě cesty mají délku rovnou výšce stromu $\log n$. Proto můžeme provést následující odhad
Obě metody lze používat i v dimenzích větších než 2. V případě kd-stromu nahradíme v $\mathbb R^d$ vertikální a horizontální přímky nadrovinami dimenze $d-1$, které jsou kolmé k některé z os a jsou tedy $d$ možných typů.
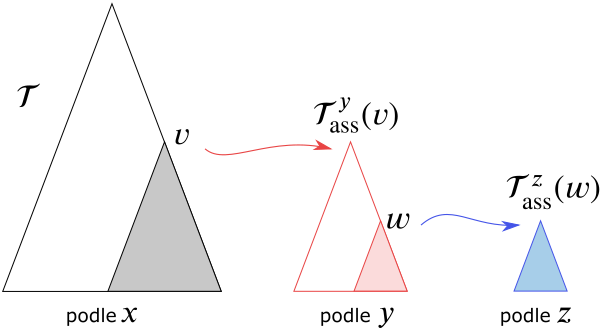
Range tree v dimenzi $d$ vytváříme jako řetězce asociovaných podstromů. V dimenzi 3 vezmeme strom $\mathcal T$, který dává uspořádání bodů množiny $P$ podle souřadnice $x$. Ke každému uzlu $\nu$ tohoto stromu vytvoříme asociovaný podstrom $\mathcal T^y_{ass}(\nu)$, který určuje pořadí podle souřadnice $y$ a konečně ke každému uzlu
$\omega$ z $\mathcal T^y_{ass}(\nu)$ vytvoříme asociovaný strom $\mathcal T^z_{ass}(\omega)$, který určuje pořadí podle souřadnice $z$. Viz obrázek 7.8.
Obrázek 7.8 Asociované stromy v dimenzi 3.
Parametry obou algoritmů v dimenzi $d\ge 2$ zachycuje následující tabulka: