Závěrečná práce: Bc. Michal Jakubík: Continually Learned Index for Dynamic Approximate Nearest Neighbor Search
Diplomová práce
Continually Learned Index for Dynamic Approximate Nearest Neighbor Search
Anotace
Moderné aplikácie sa čoraz častejšie spoliehajú na vysokodimenzionálne vektorové embeddingy na reprezentáciu dátových modalít, ako sú text, obraz alebo proteínové štruktúry. Efektívne vyhľadávanie v takýchto dátach rieši podobnostné vyhľadávanie, pri ktorom vektorové indexy, ako napríklad HNSW alebo IVF-PQ, vykonávajú aproximované vyhľadávanie najbližších susedov (Approximate Nearest Neighbor, ANN …více
Abstract
Modern applications increasingly rely on high-dimensional vector embeddings to represent data modalities such as text, images, or protein structures. Efficient retrieval of such data is addressed by similarity search, where vector indexes such as HNSW or IVF-PQ perform approximate nearest neighbor (ANN) search to find the most similar vectors to a given query. Learned indexes represent an alternative …více
Zadání práce
Learned index structures represent a promising approach to approximate nearest neighbor search in high-dimensional spaces, replacing traditional tree-based or hash-based indexing with neural network classifiers that route queries to relevant buckets. While static learned indices have demonstrated competitive retrieval performance, they fundamentally assume a fixed dataset, an assumption that rarely holds in real-world applications where data is continuously inserted and deleted. Extending learned indices with dynamic update capabilities introduces substantial challenges: the underlying classifier must grow to accommodate new buckets while maintaining balanced partitioning, and the model must be fine-tuned after structural changes without catastrophically forgetting previously learned routing decisions. Furthermore, as the data distribution evolves over time, whether gradually through incremental insertions or abruptly through distribution shift, the index may degrade to a point where full retraining becomes unavoidable. While recent work has proposed initial dynamic extensions of learned indices, a systematic and modular investigation of the key design dimensions: how to maintain representative training data, how to restructure buckets efficiently, how to adapt the model without forgetting, and how to detect the need for retraining; has not yet been conducted.
The student will design and implement Continually Learned Index that supports insertion and deletion operations with automatic classifier expansion and bucket splitting to maintain index balance. The experimental work will be organized around four independent research questions, each isolating a critical design dimension: first, the comparison of replay buffer population strategies, including random sampling, herding, and influence functions; second, the evaluation of reclustering approaches such as full reclustering, iterative splitting, and DeDrift applied to selected subsets of buckets; third, the comparison of fine-tuning loss functions, including standard cross-entropy, knowledge distillation, elastic weight consolidation, and synaptic intelligence; and fourth, the analysis of architectural adaptation strategies during fine-tuning, covering various combinations of freezing and resetting classifier and backbone weights. The best-performing technique from each dimension will then be combined into a single configuration. Additionally, the student will investigate the detection of retraining necessity, examining whether metrics such as the number of added buckets and model prediction confidence on newly inserted vectors can reliably signal when full retraining from scratch is required, both under gradual performance degradation and abrupt distribution shift. The resulting dynamic learned index will be evaluated and compared against existing baselines, including the static Learned Metric Index and other dynamic learned index implementation, in terms of retrieval accuracy, query and update latency, and memory consumption. The student will then conduct large-scale benchmarking experiments on up to 100 million vectors from subsets of the LAION-5B dataset, subset of Deep1B dataset and llama-128-ip attention and imagenet-align-640-normalized text-to-image datasets from VIBE benchmark, across static and several dynamic scenarios, including explicit simulation of distribution shifts. The source code created by the student will be publicly available in the IS MU archive under the GNU LGPL license.
20. 5. 2026 10:55, RNDr. David Procházka, učo 485104
 angličtina
angličtina
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Dynamic Learned Indexing for Vector Data Using Continual Learning
Ing. Filip Forgáč -
Temporally Dynamic Learned Index for Similarity Search over Complex Data
Mgr. Emma Sommerová, učo 514368 -
Python Libraries for Storing Embeddings on Disk
Bc. Jakub Neruda, učo 524944 -
Comparison of Neural Embeddings for Tracking Cells
Mgr. Miroslav Mažgut -
Learned Indexing in Vector Database Management Systems
Mgr. Jakub Žovák -
Extrakce informací ze sportovních přenosů
Ing. Jakub Dvořák -
Integration of an AI Copilot into Web Development Processes
Mgr. Dominik Adam -
A Quest for Information: Enhancing Game-Based Learning with LLM-Driven NPCs
Mgr. Tereza Tódová
Složky
Soubory
-
Přidání souboru
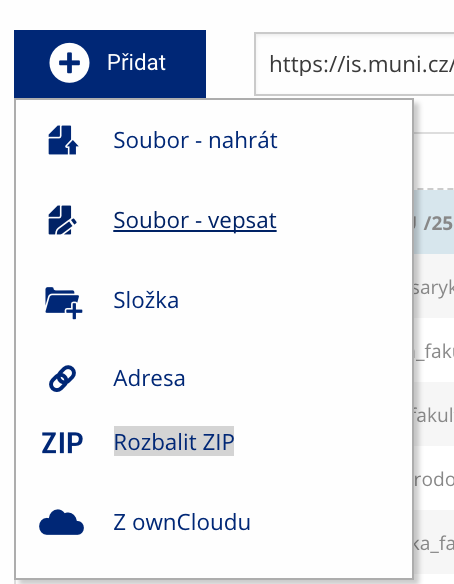 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
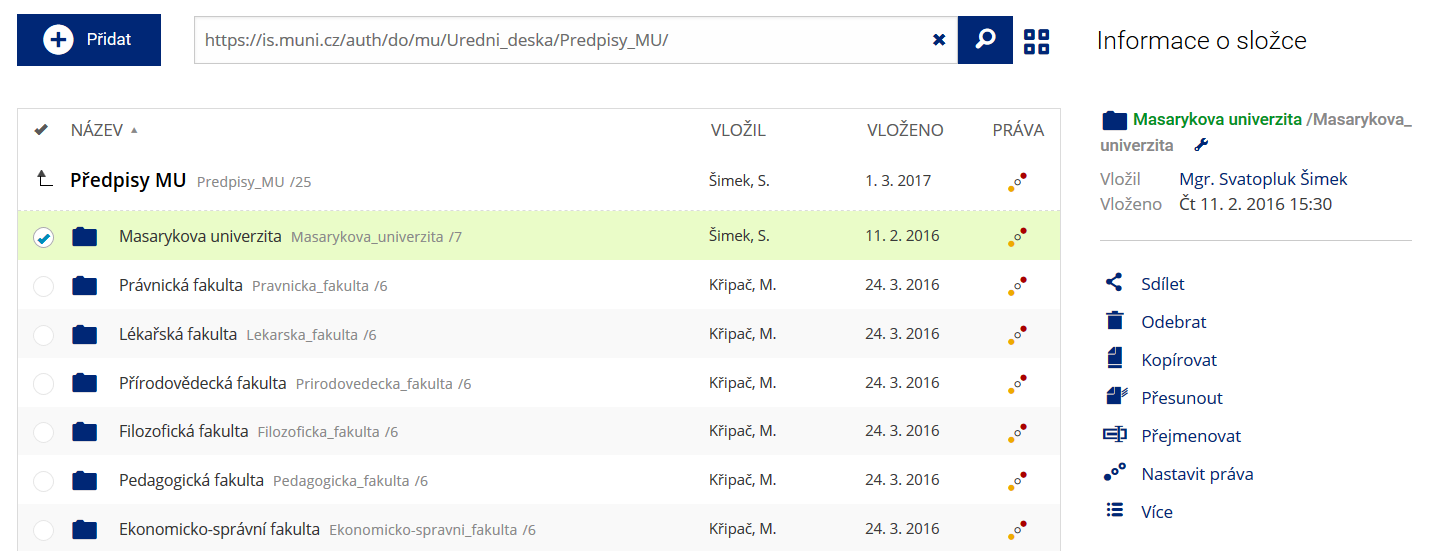 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
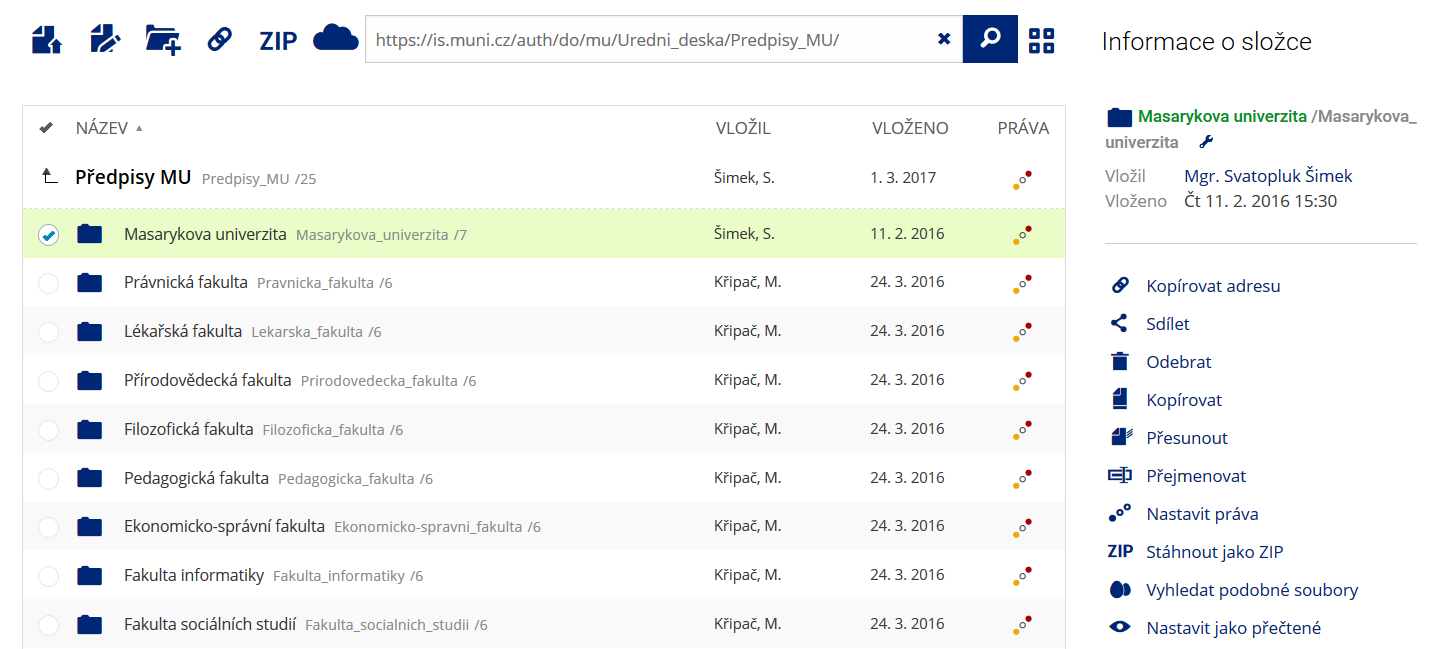 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
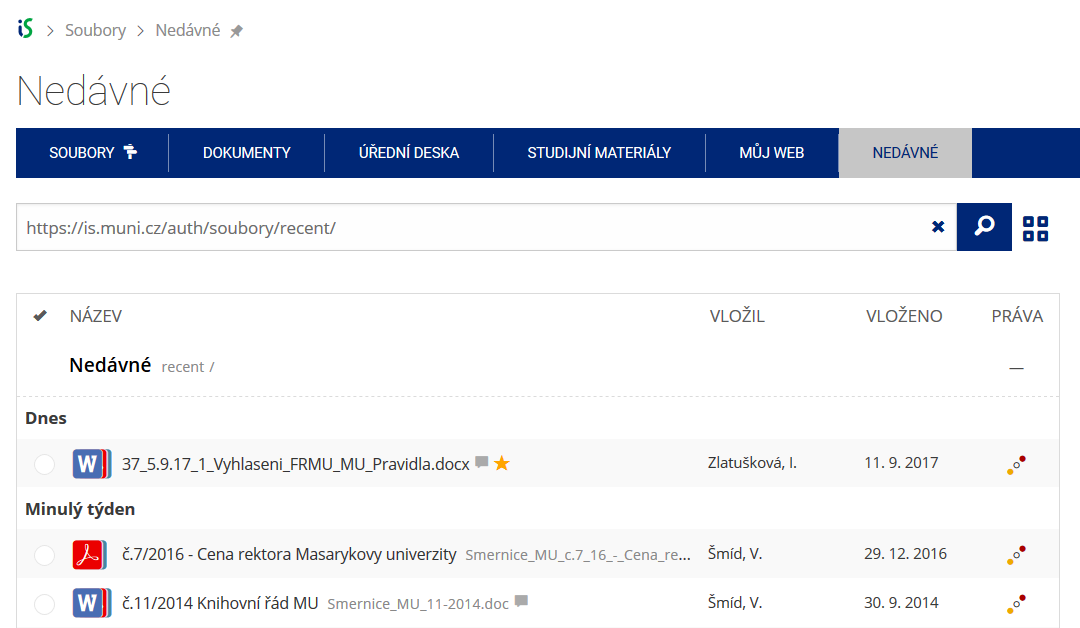 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.