Závěrečná práce: Bc. Marek Kadlčík, učo 485294: Improving Arithmetical Reasoning of Language Models
Diplomová práce
Improving Arithmetical Reasoning of Language Models
Anotace
Práce se zabývá zlepšováním jazykových modelů pro řešení matematických slovních úloh. Nejdříve pročištíme a převedeme existující datové sady, abychom vytvořili Calc-X, standardizovanou sbírku 300 000 matematických příkladu a řešení s postupem. Demonstrujeme, že Calc-X je vhodný pro tréning jazykových modelů, které interagují s kalkulačkou pro počítání mezivýsledků při řešení matematických úloh. Ukazujeme …více
Abstract
This work focuses on improving language models for solving math word problems. First, we clean and transform existing datasets to create Calc-X, a standardized collection of 300,000 math problems with step-by-step solutions. We demonstrate that Calc-X is suitable for training language models interacting with a calculator to compute intermediate results when solving math problems. We show that such …více
Zadání práce
1. Dataset curation
The work will review existing datasets for arithmetical reasoning, organize them into a consistent format with explicit annotations of calculations and remove data leaks between train and test split with an n-gram lexical overlap method.
2. Training calculator-using models
The work will implement an inference method for language models that enables interaction with a calculator within generation, train calculator-using models of two sizes with supervised learning on the created dataset, and compare their accuracy to the traditional generation.
3. Self-training
Additionally, the work will develop a prototype of offline and online self-training to explore their potential for autonomously improving model accuracy. The offline experiment includes generating predictions on a subset of the training dataset using a trained model and applying selected preference-optimization methods to align the model toward generating solutions with a correct result. In the online setup, predictions will be generated dynamically during self-training.
Both experiments will compare the accuracy of preference-optimization methods to a self-training baseline with a supervised next-token cross-entropy loss.
27. 5. 2024 10:43, Mgr. Michal Štefánik, Ph.D., učo 422237
 angličtina
angličtina
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Měření pobouření na českém Twitteru
Bc. Petr Rusnok -
Měření pobouření na českém Twitteru
Bc. Petr Rusnok -
Axes of Robustness of Neural Language Models
Mgr. Michal Štefánik, Ph.D., učo 422237 -
Data analysis for nuclear magnetic resonance spectroscopy
RNDr. David Porteš -
Anomaly Detection Using Deep Sparse Autoencoders for CERN Particle Detector Data
Bc. Filip Široký, učo 445415 -
Neuronové sítě a jejich aplikace
Mgr. Erik Benovič, učo 502902 -
Detekce objektů v průmyslových datových množinách
Mgr. Hai Duong Tran -
Automatization of grouting robots hardware optimization
Mgr. Ronald Luc, učo 235313
Složky
Soubory
-
Přidání souboru
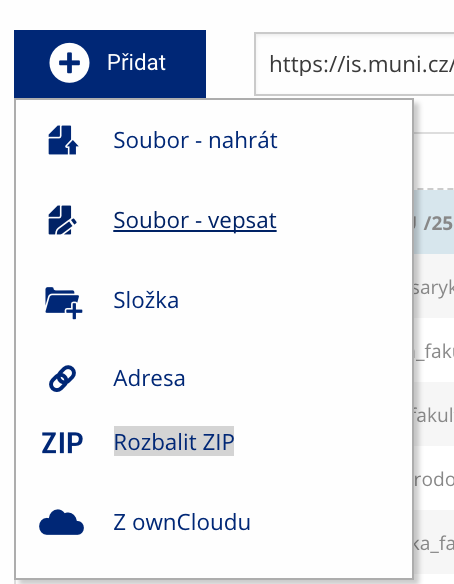 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
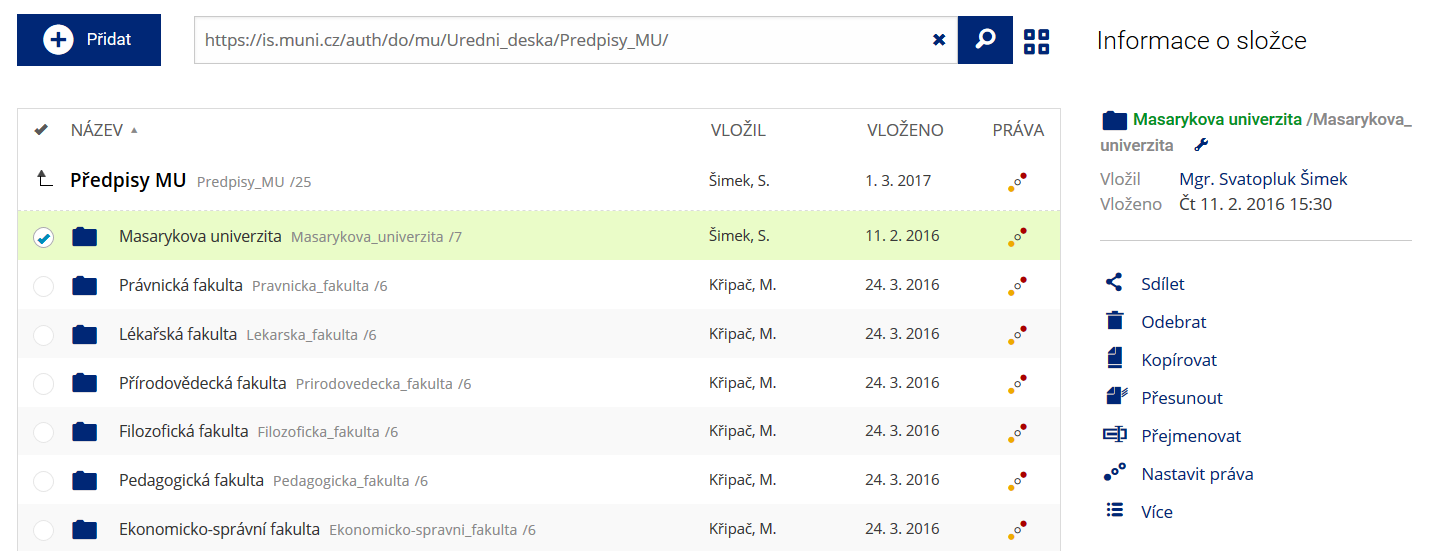 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
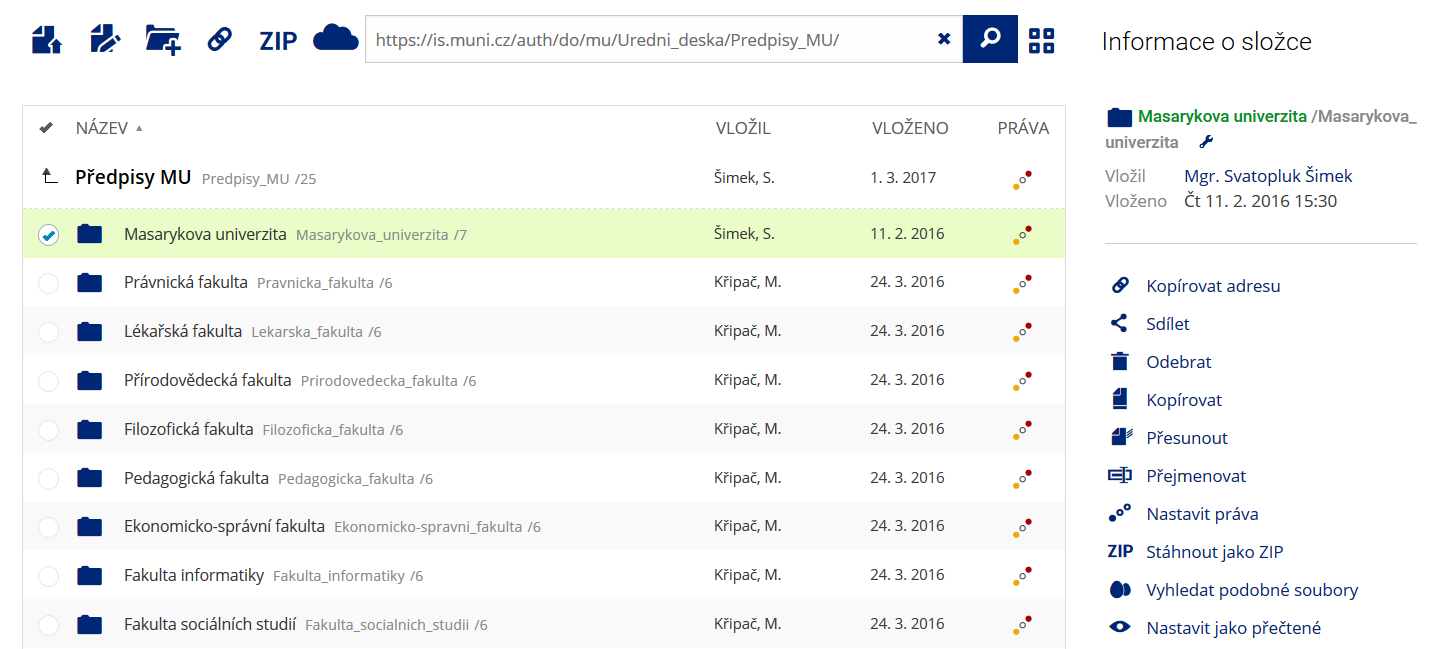 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
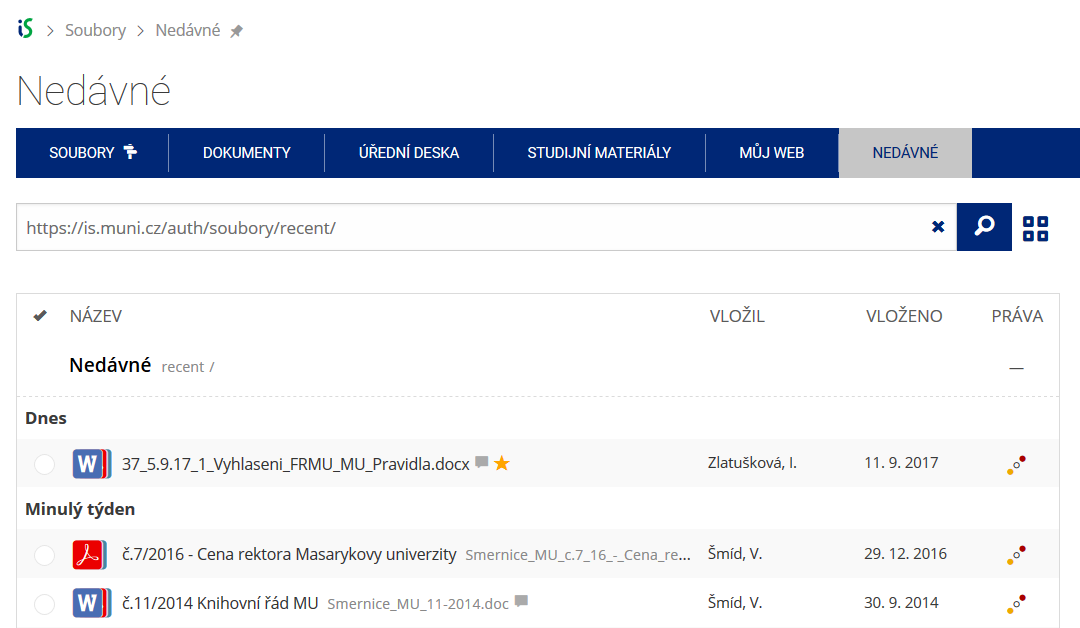 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.