Závěrečná práce: Jakub Žovák: Fast Similarity Searching of Text Documents using Learned Metric Index
Bakalářská práce
Fast Similarity Searching of Text Documents using Learned Metric Index
Anotace
Textové dokumenty, ako sú blogy, statusy na sociálnych sieťach, spravodajské články, eseje a textové správy, predstavujú jeden z hlavných zdrojov informácií na internete. Preto je mimoriadne dôležité takéto dáta efektívne indexovať a vyhľadávať. Keďže sú však textové objekty rozsiahle a komplexné, hľadanie presnej zhody je prakticky nemožné. Preto sa tieto objekty musia vyhľadávať na základe podobnosti …více
Abstract
Text documents such as blog posts, tweets, news articles, essays, and text messages, represent one of the primary sources of information on the internet. Therefore, it is paramount to index and search such data efficiently. However, since these objects are large and complex, searching for an exact match is practically impossible. Therefore, text objects must be searched based on the notion of similarity …více
Zadání práce
24. 5. 2022 09:06, RNDr. Matej Antol, Ph.D., učo 325040
 angličtina
angličtina
Konzultant
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Implementace Learned Metric Index
RNDr. Terézia Slanináková, Ph.D., učo 445526 -
Implementation of Unsupervised Learned Metric Index
Mgr. Vojtěch Kaňa -
Indexing Data Using Machine Learning
Mgr. Jakub Hanko -
Enhancing Performance of Learned Metric Index for Indexing Large Datasets
Bc. Jozef Čerňanský -
Application of machine learning to searching in unstructured data
RNDr. Terézia Slanináková, Ph.D., učo 445526 -
Propaganda Detection using Stylometric Text Analysis
RNDr. Radoslav Sabol, učo 469331 -
Propojení pojmenovaných entit získaných z českých biomedicínských textů se standardními slovníky
Mgr. Filip Gregora -
Analysis of use of AI systems in writing final theses at FI MU
Ing. David Černý
Složky
Soubory
-
Přidání souboru
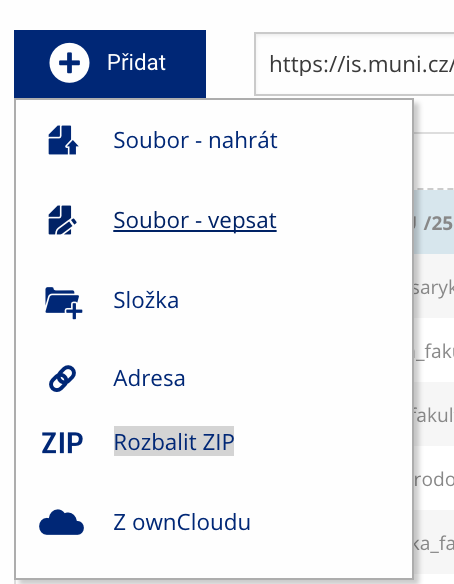 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
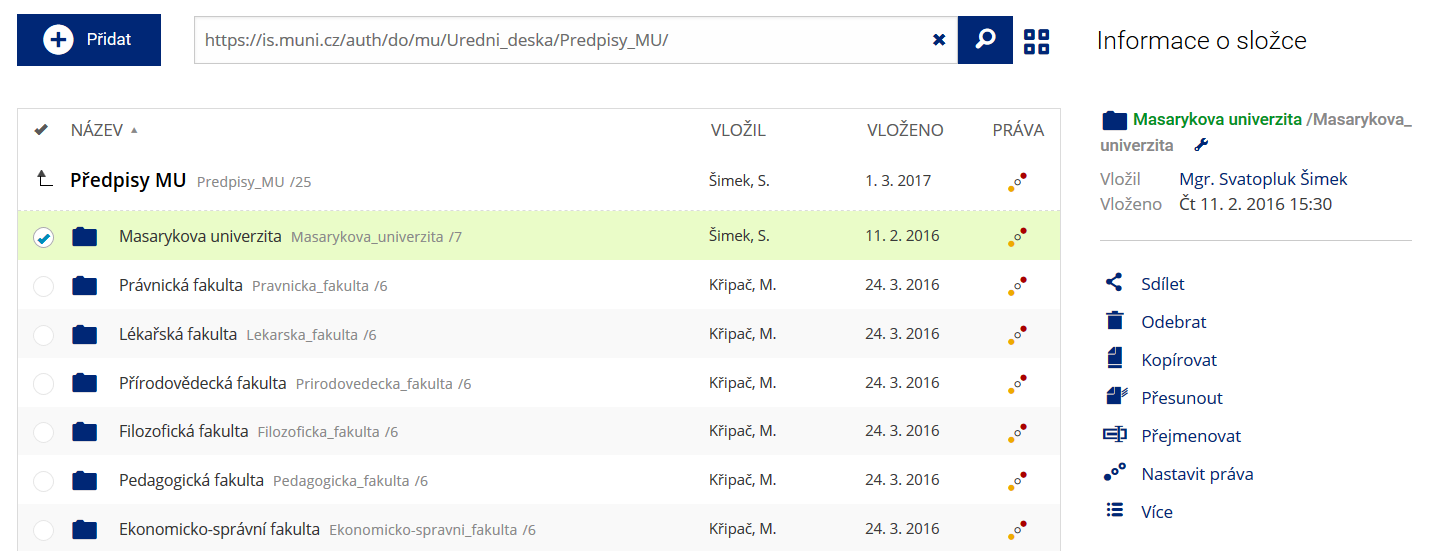 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
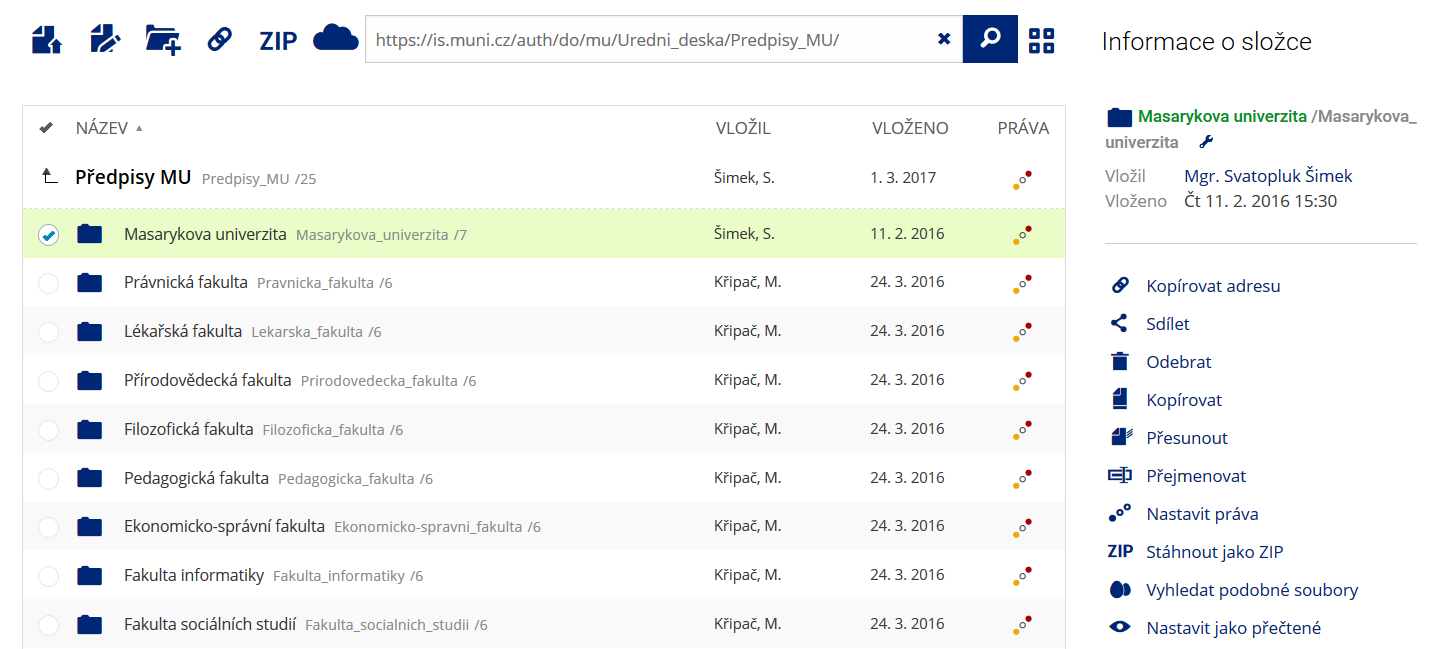 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
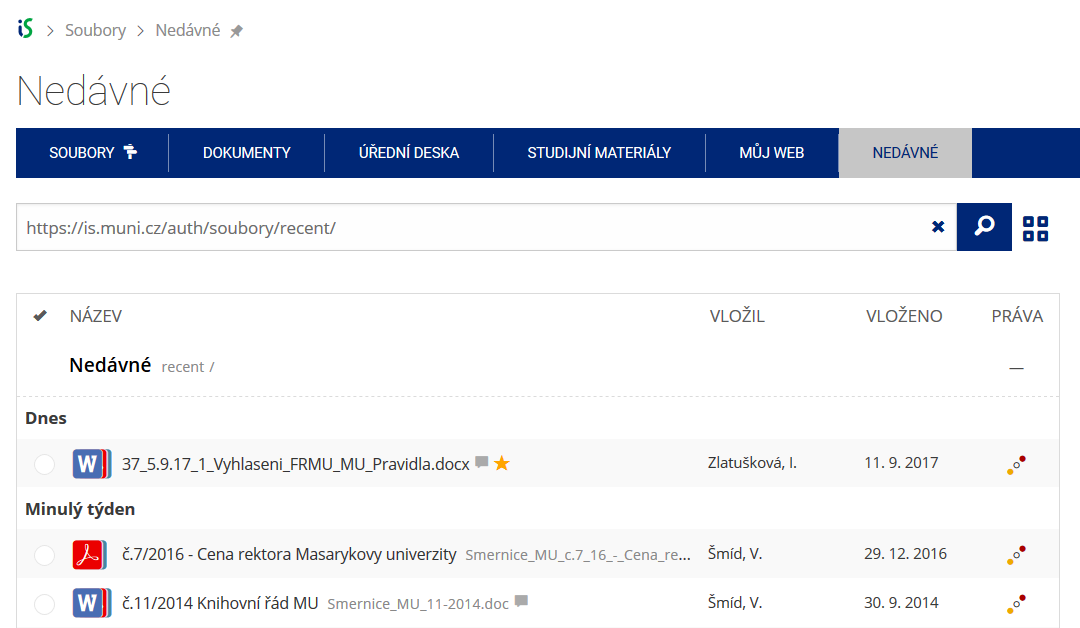 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.