Závěrečná práce: Bc. Tomáš Houfek: Mining Czech Clinical Notes Using the Language Modelling Technology
Diplomová práce
Mining Czech Clinical Notes Using the Language Modelling Technology
Anotace
V této práci pracuji s několika velkýmu jazykovými modely. Tyto modely předtrénuji na velké datové sadě lékařských zpráv a následně je dotrénuji na skecifické úkoly v lékařské doméně. První je rozpoznávání lékařskýhc jmených entit a druhý klasifikace lékařských zpráv. Na těchto dvou úkolech předvedu, že předtrénování na velkých lékařských datech vylepší výsledky těchto dvou úkolů a to netriviálně oproti …více
Abstract
In this thesis I work with various Large Language models, pre-train these models on a large Czech medical dataset and then fine-tune these models on a pair of natural language processing tasks in the medical domain. The first is Medical Named Entity Recognition (Medical Named Entity Recognition (NER)) and the second is Medical records classification. I show that further pre-training on the large medical …více
Zadání práce
Patient records are a goldmine for various data analytics and machine learning applications aiming at gaining insights that could lead to more efficient treatments, inform innovative clinical decision support systems and enable patient empowerment. However, a lot of information in patient records is "locked" in the form of unstructured text that is not readily amenable to machine processing. The latest advances in the language models technology can be used for tackling this challenge. However, few such models exist for relatively under-resourced languages like Czech, and there are no such models at all trained specifically for the medical domain in the Czech context, which is a gap this work will address.
Goals:
- Study the state of the art in general-purpose language models trained on English texts.
- Review language models specifically trained on biomedical text. Focus on both self-supervised learning stage and consequent fine-tuning techniques.
- Implement a bespoke language model trained on Czech (bio)medical content (e.g. patient records) in a self-supervised manner.
- Work with clinical expert(s) on defining a specific unmet clinical need that could be used for task-specific fine-tuning of the self-supervised model (e.g. extraction of named entities such as symptoms, procedures or medications from unstructured health records).
- Explore approaches that could support the results of the developed model with explanations (getting inspired for instance by LIME or gradient-based attribution methods).
- Validate the result with the assistance of the clinical expert.
- Write up the results in a thesis form.
Requirements:
- Keen interest in the topic.
- Knowledge of and previous hands-on experience with natural language processing.
- While the thesis can be written and defended in Czech, its elaboration and presentation in English will be supported enthusiastically (the results may be disseminated to and used by partners in ongoing or future EU projects).
- Monthly (or more frequent, if needed) progress review meetings with the supervisor will be expected.
- The student(s) will also be expected to develop and document any related code using the FI MU Gitlab and ICS SensitiveCloud platforms, and (if applicable) re-use and interact with other related projects there.
25. 5. 2024 08:33, doc. Mgr. Bc. Vít Nováček, PhD, učo 4049
 angličtina
angličtina
Oponent
Institute of Formal and Applied Linguistics, Charles University, Czech Republic, Faculty of Mathematics and Physics
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Data extraction from medical records
Mgr. Tomáš Houfek -
Anonymisation of Clinical Notes
Bc. Karolína Rusnačková -
Patient similarity based on unstructured clinical notes
RNDr. Petr Zelina, učo 469366 -
Czech Question Answer Selection using Recurrent Neural Networks
RNDr. Radoslav Sabol, učo 469331 -
Large Language Models for Social Robot Communication
Bc. Filip Brzý -
Domain-specific English-Czech Neural Machine Translation
Mgr. Martin Wörgötter -
Analysis of use of AI systems in writing final theses at FI MU
Ing. David Černý -
Propaganda Detection using Stylometric Text Analysis
RNDr. Radoslav Sabol, učo 469331
Složky
Soubory
-
Přidání souboru
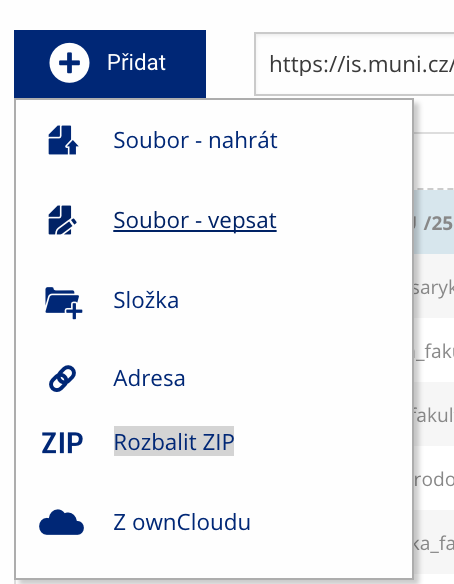 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
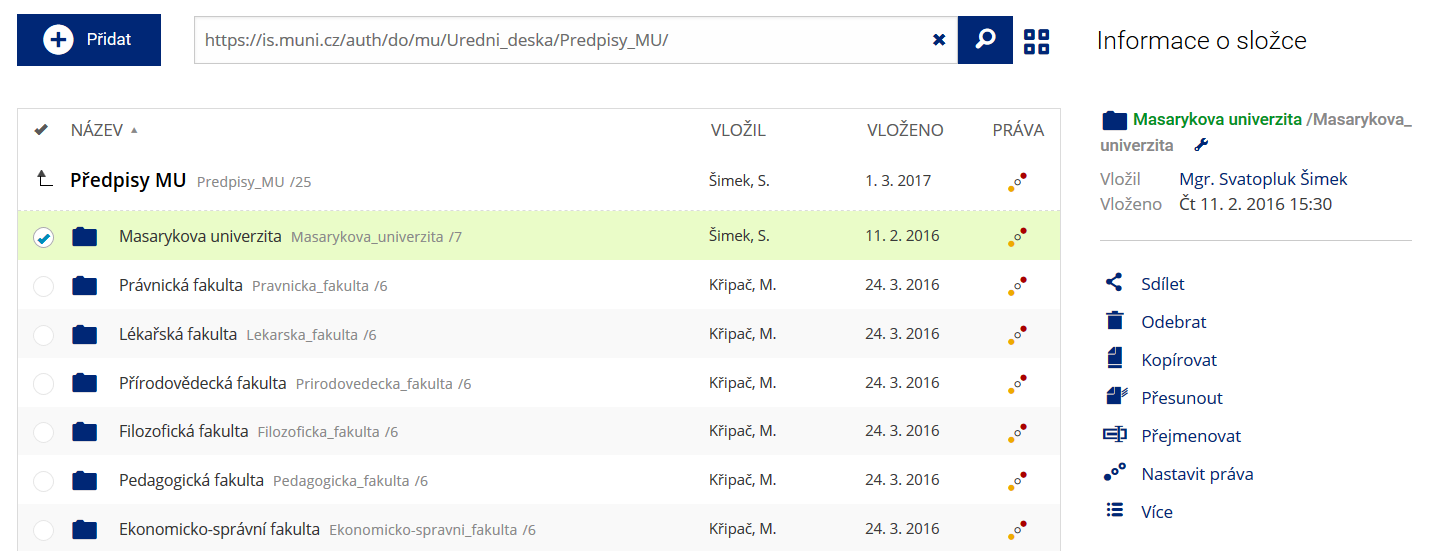 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
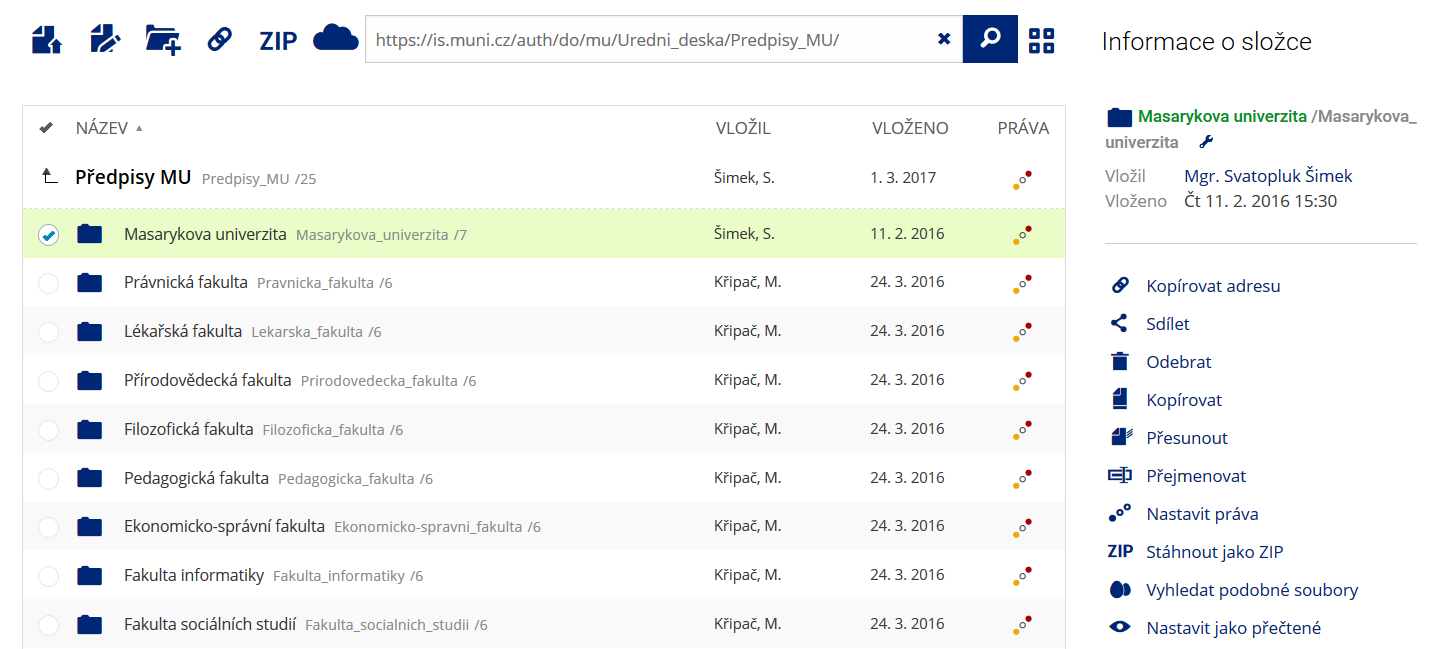 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
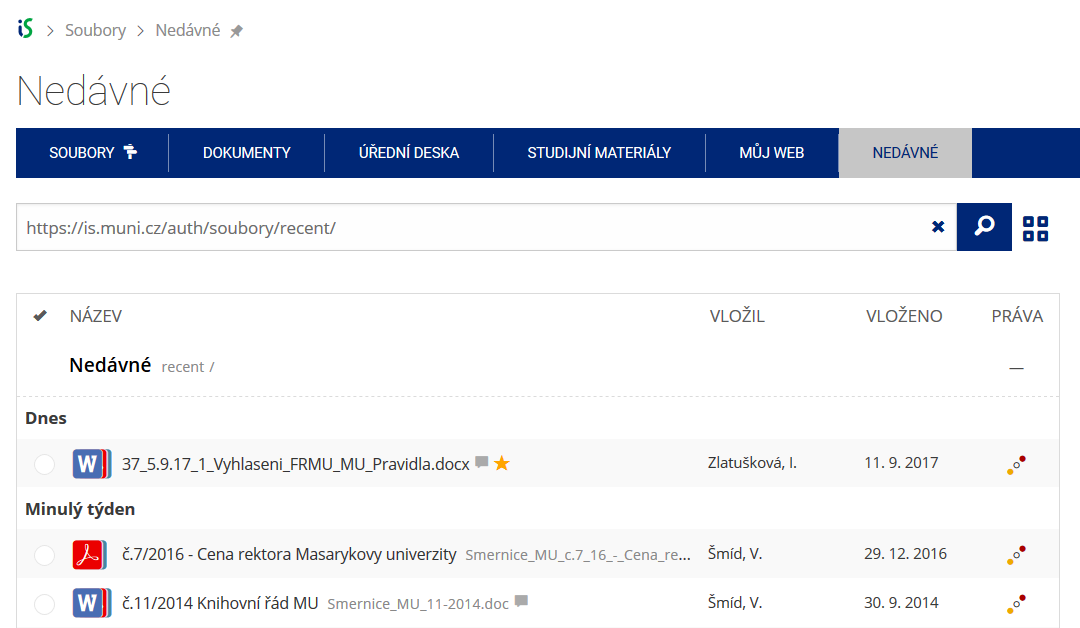 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.