Závěrečná práce: Michal Starý: Prediction of missing peaks in mass spectra
Bakalářská práce
Prediction of missing peaks in mass spectra
Anotace
Identifikace sloučenin je zásadní pro monitorování životního prostředí. Plynová chromatografie s hmotnostní spektrometrií (GC-MS) je široce používanou metodou pro tuto identifikaci. Klíčovým krokem ve zpracování komplexních dat pocházejících z GC-MS přístroje je detekce vrcholů. Chyby algoritmů detekce vrcholů, jako jsou například nezachycené vrcholy, značně omezují schopnost výzkumníků monitorovat …více
Abstract
Compound identification is essential for monitoring the environment. Gas Chromatography-Mass Spectrometry (GC-MS) is a widely used method for such identification. A crucial step in the processing of complex data coming from the physical GC-MS instrument is peak detection. The errors of peak detection algorithms, such as missed peaks, severely limit the researchers' ability to monitor low-concentration …více
Zadání práce
17. 12. 2021 16:25, Mgr. Aleš Křenek, Ph.D., učo 3086
 angličtina
angličtina
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Fast object detection on mobile platforms using neural networks
Mgr. Tomáš Repák -
Synthesis of microscopy images using neural networks
Bc. Martin Kozlovský -
Automatic text summarization
Mgr. Adam Hájek -
Mining Czech Clinical Notes Using the Language Modelling Technology
Mgr. Tomáš Houfek -
Smart Picture Enlargement Using Neural Networks
Ing. Michal Čaniga -
Forecasting of successful verbal memory encoding in humans from intracranial EEG
Mgr. Patrik Begáň -
Basket opce
Mgr. Tomáš Ličák -
Pathological Image Analysis Using Attention Based Deep Learning Methods
Ing. Petr Kantek, B.Sc.
Složky
Soubory
-
Přidání souboru
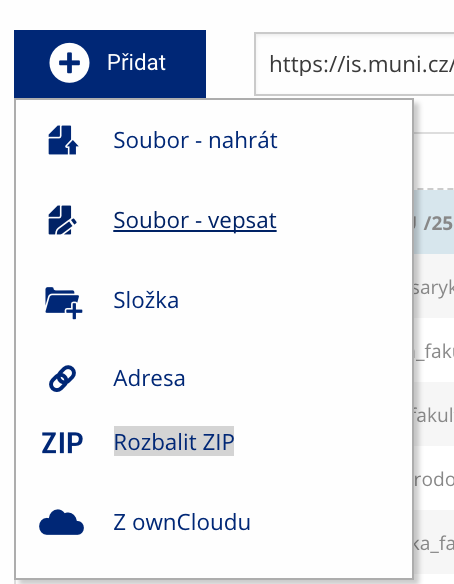 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
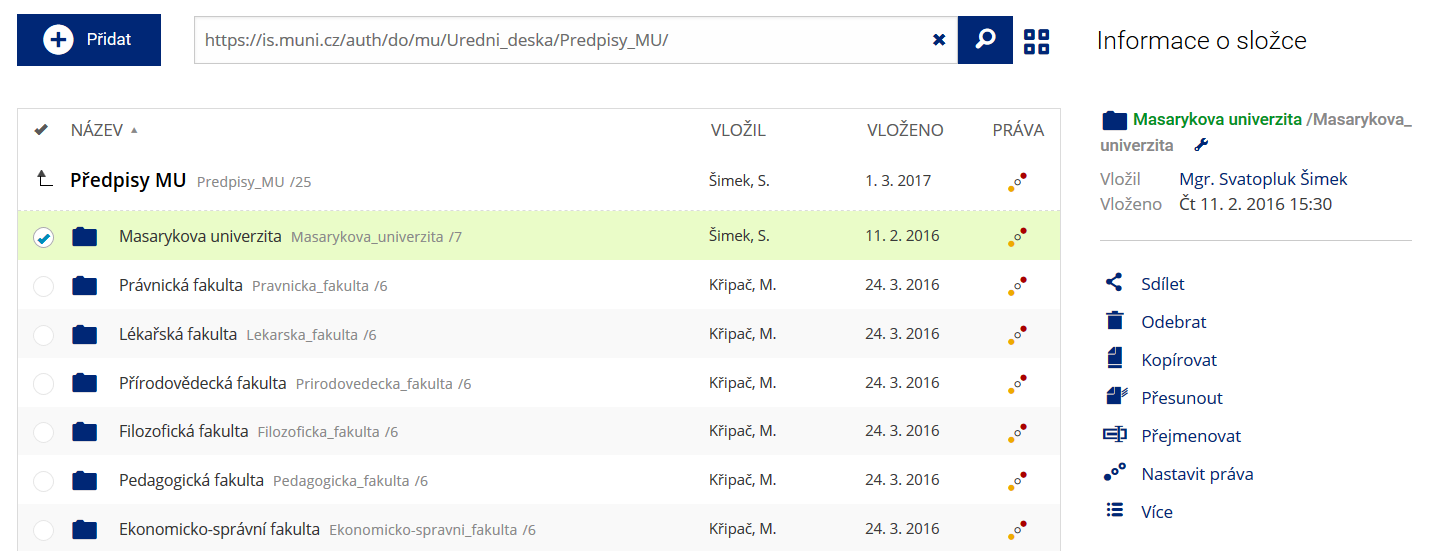 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
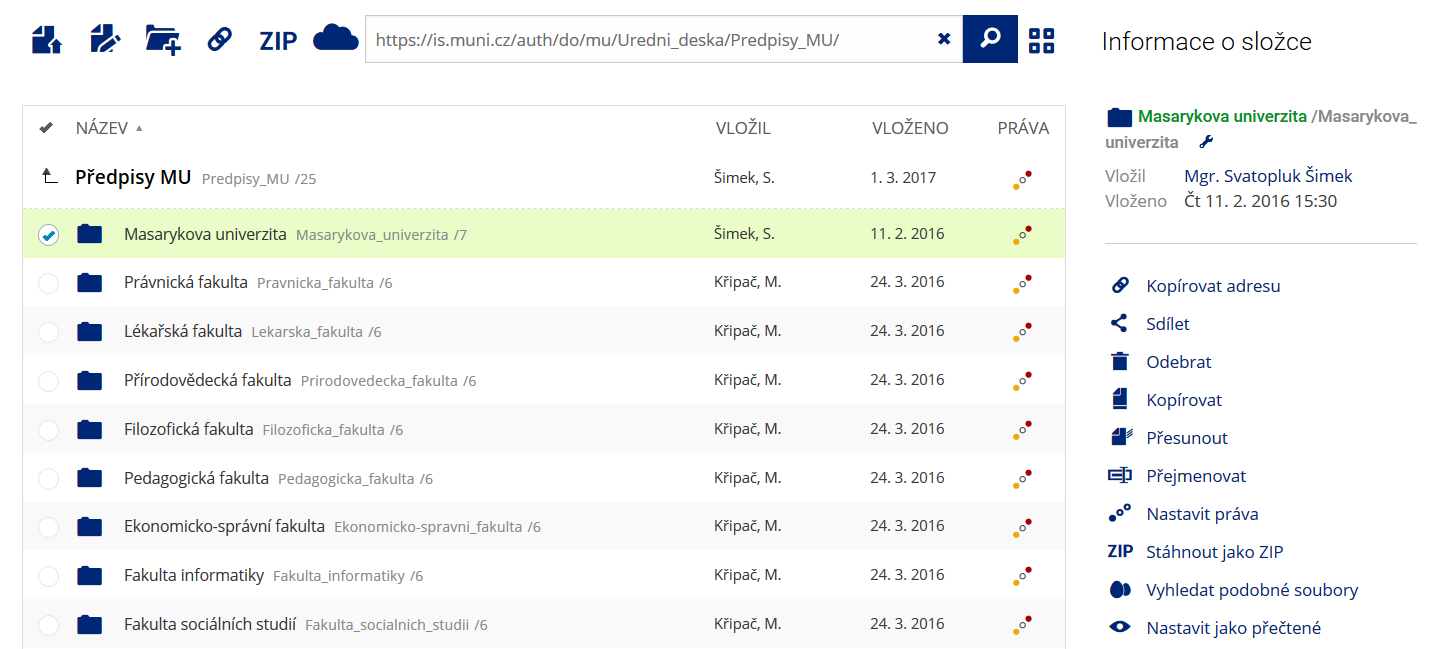 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
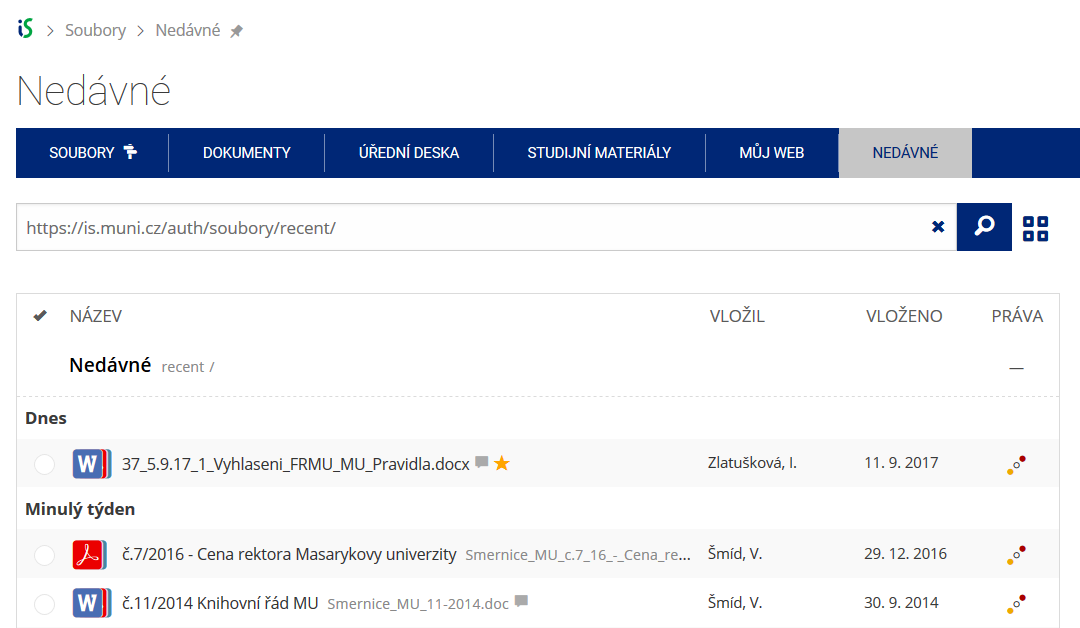 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.