Závěrečná práce: Bc. Šimon Plhák: A High-Performance Dynamic Learned Index for Complex Data in Rust
Diplomová práce
A High-Performance Dynamic Learned Index for Complex Data in Rust
Anotace
Tato diplomová práce se zabývá vývojem vysoce výkonného učeného indexu (learned index) pro vyhledávání podobnosti v jazyce Rust, který nahrazuje předchozí prototyp v Pythonu. Index využívá kaskádu statických indexů založených na osvědčených technikách datových struktur a k řízení procesu vyhledávání využívá modely strojového učení. Implementace zahrnuje nativní trénovací pipeline pro strojové učení …více
Abstract
This thesis develops a high-performance learned index for similarity search in Rust, replacing previous Python prototype. The index utilizes a cascade of static indexes rooted in proven data structure techniques, employing machine learning models to guide the search process. The implementation features a native ML training pipeline, custom nearest-neighbor problem optimization, and Python interoperability …více
Zadání práce
Similarity search over collections of complex data, such as images, proteins, or human motion sequences, is a fundamental challenge in modern data management, and the rapid growth of these collections demands increasingly efficient indexing methods. Learned indexes, which employ machine learning models to guide the search process in place of or alongside traditional index structures, have emerged as a promising direction for accelerating nearest neighbor queries. To be practical in real-world scenarios where data evolves over time, such indexes must also support dynamic operations, namely insertions and deletions, without sacrificing search quality. A particularly compelling approach achieves dynamicity temporally: rather than performing in-place structural modifications on a single monolithic index, a collection of static indexes is maintained and progressively compacted, following principles akin to the Bentley–Saxe framework. This design enables efficient insertion through merging strategies and supports deletion via mechanisms such as a global dictionary for weak deletes or the targeted rebuilding of specific index levels. However, existing research prototypes of such dynamic learned indexes are predominantly implemented in Python, which inherently limits their runtime performance, memory efficiency, and scalability to truly large datasets. Reimplementing the performance-critical components in Rust offers a path to overcoming these limitations, leveraging the language's native performance, safe memory management, and zero-cost abstractions.
The student will design, implement, optimize, and rigorously evaluate a temporally dynamic learned index for complex data in Rust, using an existing Python implementation built upon a static learned index (Learned Metric Index) as the starting point for the overall design. The resulting implementation must support insert, bulk load, delete, and approximate k-nearest neighbor search operations, with query execution guided by learned models, as well as cold storage of larger index levels to disk to reduce memory overhead for very large datasets. As part of the implementation, the student will build a native machine learning training pipeline in Rust, encompassing model training, clustering, and configurable retraining strategies, and will justify relevant technical decisions, such as the choice of machine learning framework, through comparative analysis. To ensure interoperability with the existing research codebase, the student will create Python bindings using PyO3 and Maturin, including a facade layer enabling seamless swapping between the Python and Rust implementations. The student will then conduct large-scale benchmarking experiments on up to 100 million vectors from subsets of the LAION-5B dataset, subset of Deep1B dataset and llama-128-ip attention and imagenet-align-640-normalized text-to-image datasets from VIBE benchmark, across static and several dynamic scenarios, including explicit simulation of distribution shifts. The proposed architecture will be benchmarked against reference methods, such as IVFFlat from the FAISS library and static and dynamized versions of the Learned Metric Index, analyzing the trade-offs between update throughput, search effectiveness and efficiency (recall and latency), and memory overhead. The thesis will present the resulting system architecture, document the design decisions, and provide a thorough experimental evaluation with reproducible benchmarks. The source code created by the student will be publicly available in the IS MU archive under the GNU LGPL license.
20. 5. 2026 11:01, RNDr. David Procházka, učo 485104
Přílohy
 angličtina
angličtina
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Fast Similarity Searching of Text Documents using Learned Metric Index
Mgr. Jakub Žovák -
Dolování informací z textů na základě nízkorozměrných reprezentací
Bc. Riva Nathans, BA -
Constructivist Methods of Teaching Information Retrieval
Ing. Kristián Malák -
Information extraction for news analytics
Bc. Petra Hana Štěpánová -
Klasifikace komponent získaných z dat funkční magnetické rezonance pomocí analýzy nezávislých komponent
Mgr. Barbora Pavlíčková -
Nástroj pro odhalování plagiátů v esejích
Mgr. Michal Štefánik, Ph.D., učo 422237 -
Distribuované učení rozhodovacích stromů
Mgr. Michal Štefkovič, učo 166042 -
Predikce vlivu aminokyselinové substituce na funkci proteinu
Bc. Jakub Tischler, učo 323491
Složky
Soubory
-
Přidání souboru
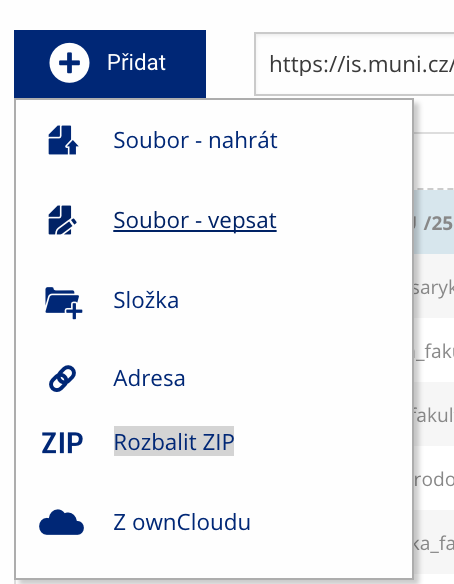 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
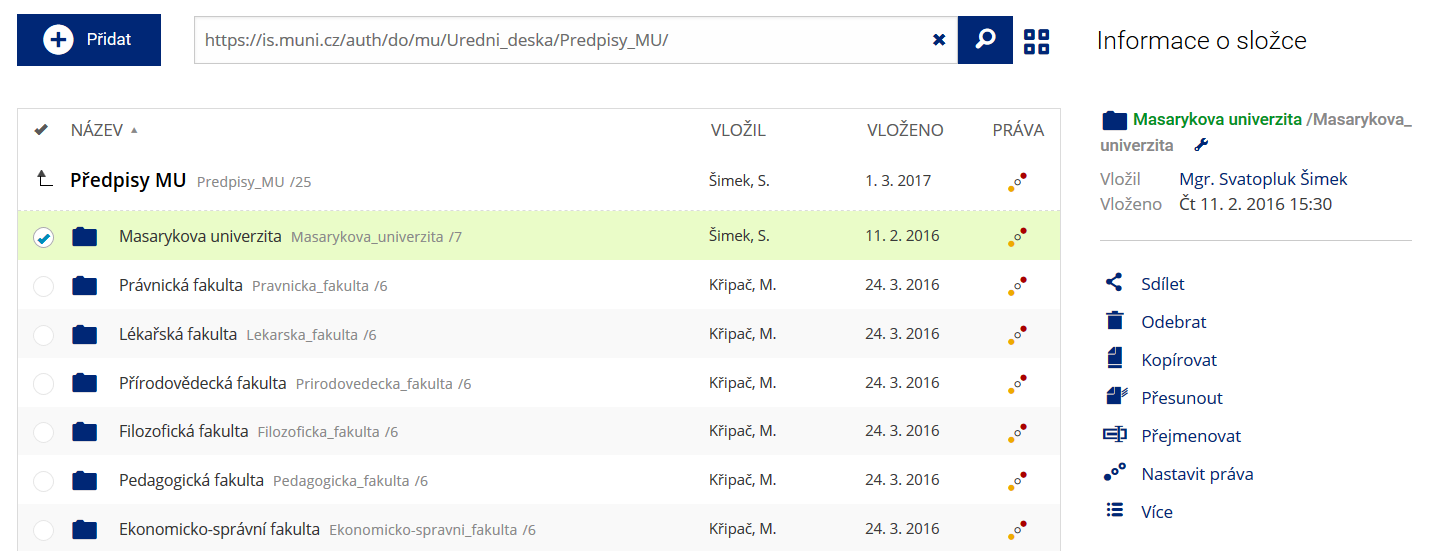 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
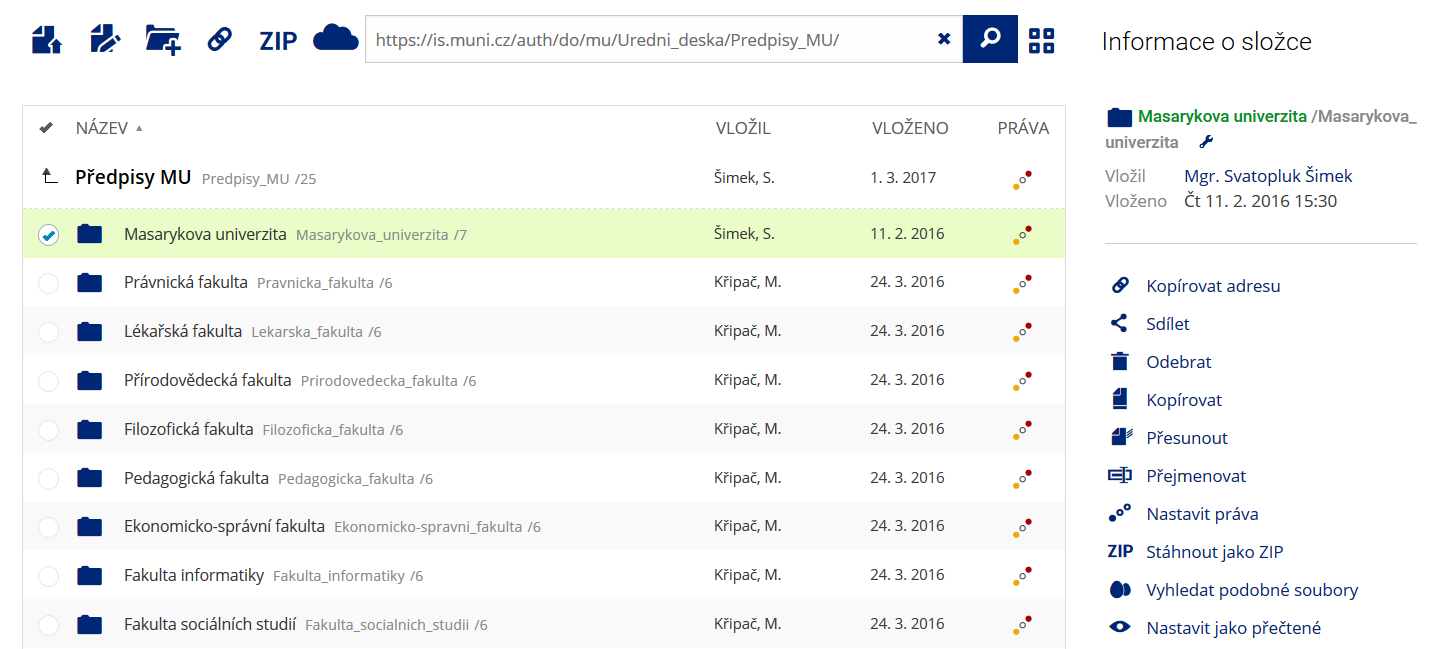 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
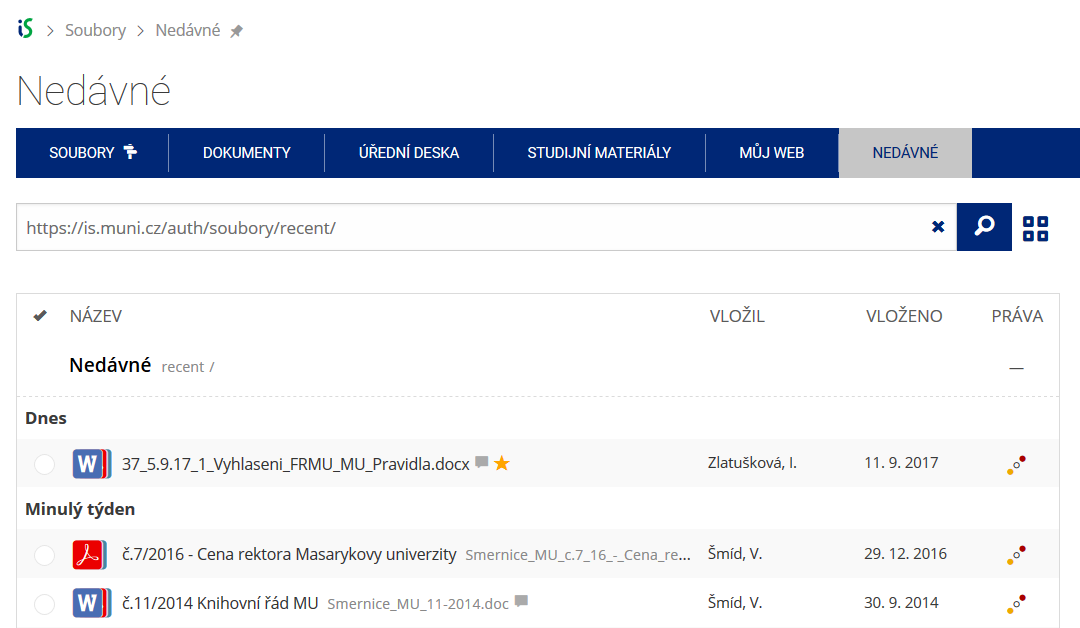 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.