Závěrečná práce: RNDr. Vít Suchomel, učo 139723: Better Web Corpora For Corpus Linguistics And NLP
Disertační práce
Better Web Corpora For Corpus Linguistics And NLP
Anotace
Počítačoví lingvisté využívají internet jako zdroj obrovského množství textových dat k rozličným úkolům zpracování přirozeného jazyka a jazykovým studiím. Internetové korpusy můžeme vytvářet ve velikostech steží dosažitelných pomocí tradičních metod sestavování korpusů. Tato práce představuje stahovač navržený k získávání textů z internetu. Umožňuje sestavovat velké textové korpusy pro úlohy zpracování …více
Abstract
The internet is used by computational linguists, lexicographers and social scientists as an immensely large source of text data for various NLP tasks and language studies. Web corpora can be built in sizes which would be virtually impossible to achieve using traditional corpus creation methods. This thesis presents a web crawler designed to obtain texts from the internet allowing to build large text …více
1. 7. 2020 13:47, doc. Mgr. Pavel Rychlý, Ph.D., učo 3692
 angličtina
angličtina
Oponenti
FF UK v Praze, Ústav Českého národního korpusu
University of Leeds, School of Languages, Cultures and Societies
Práce na příbuzné téma
Seznam prací, které mají shodná klíčová slova.
-
Corpora from reddit.com texts
Mgr. Jan Brichta -
Topic Classification for Web Corpora: Method Comparison and Crosslingual Transfer
Mgr. Rastislav Papčo -
Návrh a implementace algoritmu pro analýzu a komparaci edukačně-medicínských dat
Mgr. Kateřina Ježová -
Token-level Language Identification Using Pre-trained Language Models
Bc. Emma Bednaříková, učo 536251 -
Vergleichende Analyse der Sprache der Zeitungen "Die Tagespost" und "Mainpost"
Mgr. et Mgr. Pavel Peřina -
Learner Translation Corpus: CELTraC (Czech-English Learner Translation Corpus)
Mgr. Kristýna Štěpánková -
Porovnávání textových dat z oblasti lékařských a zdravotnických oborů
Mgr. Petra Růžičková -
Mapa akcií pre verejnosť
Mgr. Lenka Horváthová
Složky
Soubory
-
Přidání souboru
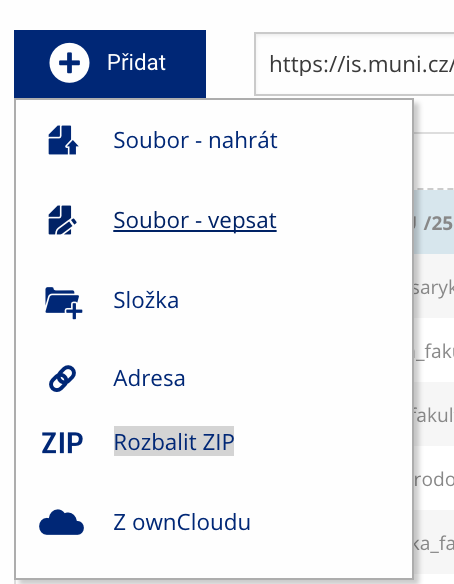 Soubor nebo složku lze nahrát pomocí tlačítka Přidat.
Soubor nebo složku lze nahrát pomocí tlačítka Přidat. -
Další operace se soubory
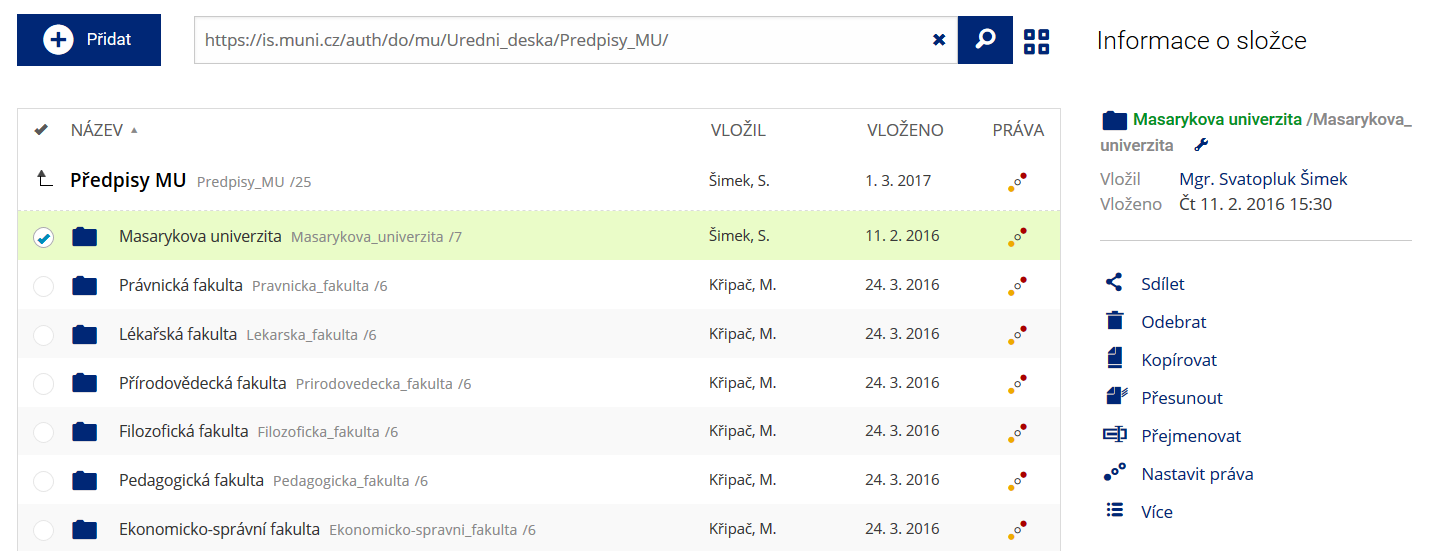 Podrobnosti lze zjistit označením příslušného řádku.
Podrobnosti lze zjistit označením příslušného řádku. -
Pohled pro experty
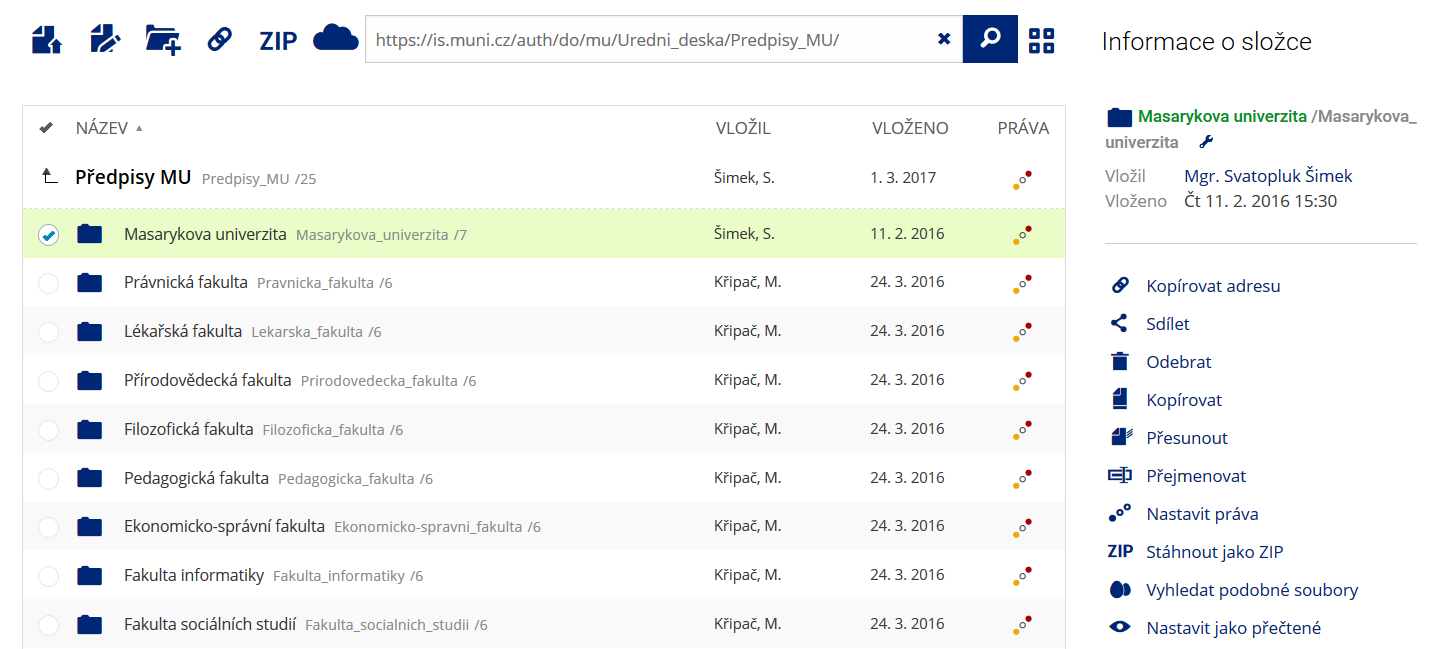 Pro častou práci je možné zvolit režim Více možností.
Pro častou práci je možné zvolit režim Více možností. -
Vyhledávání souborů
 Vyhledávaný výraz můžete zadat přímo do adresního řádku.
Vyhledávaný výraz můžete zadat přímo do adresního řádku. -
Rychlý přístup k souborům
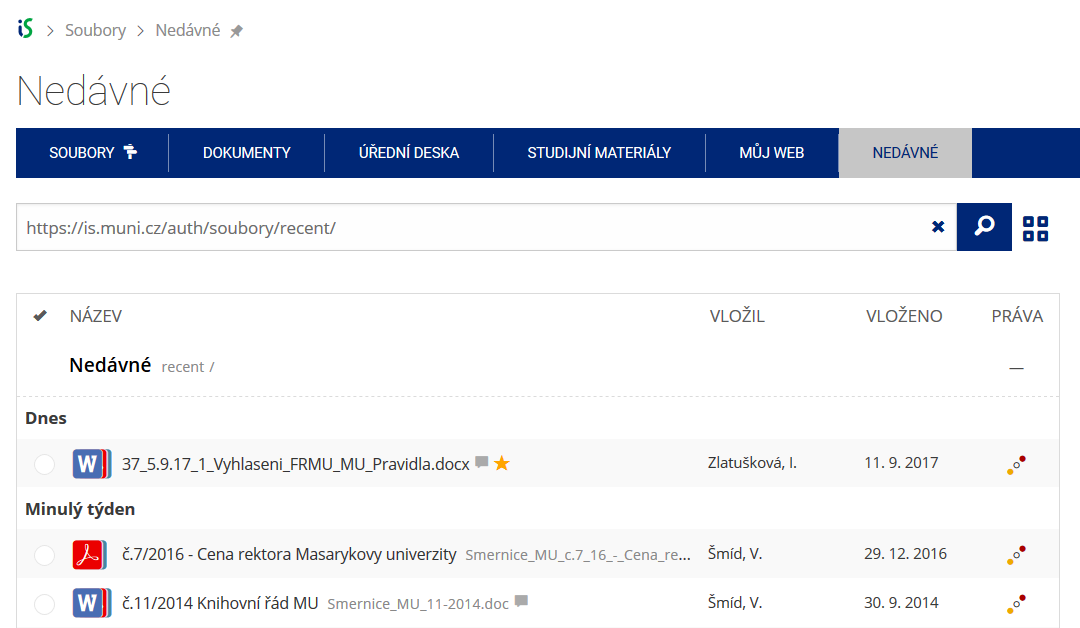 Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.
Pomocí funkce Nedávné je možné se rychle vrátit k právě prohlíženým souborům. Oblíbené soubory je také možné označit Hvězdičkou.