Připojení sítě FI do vnějšího světa
Již od vzniku Fakulty Informatiky je fakultní síť připojena do sítě Masarykovy univerzity pomocí softwarových routerů založených na operačním systému Linux. Oproti dedikovaným hardwarovým směrovačům (používá se moderní byť technicky poněkud nesmyslný termín Layer 3 switch) se jedná o řešení, které je výrazně flexibilnější, konfigurovatelnější, a v neposlední řadě levnější. Hardwarové směrovače na horním konci výkonového spektra (v dnešní době s propustností řádově stovek gigabitů za sekundu) oproti tomu poskytují větší výkon za násobně větší cenu. Požadavky sítě FI se ale po celou dobu pohybovaly pod hranicí absolutní síťové špičky, a ani síť MU většinou neumožňovala připojení tou nejrychlejší současnou technologií, takže naše řešení je plně dostačující.
Z důvodu zvýšení spolehlivosti a možnosti použít běžný serverový hardware (jeden z prvních linuxových routerů FI byl dokonce počítač s procesorem AMD K5 umístěný ještě v desktopové skříni) jsme postupně začali používat dvojici navzájem redundantních routerů, připojených do všech sítí, mezi kterými pak tyto počítače směrovaly provoz. Oba routery jsou plně zastupitelné, mají stejnou konfiguraci softwaru, a navzájem se monitorují pomocí nástrojů pro vysokou dostupnost. V případě výpadku primárního serveru je pak sekundární schopen převzít jeho roli podle aktuálního nastavení v řádu desítek sekund.
Routery sítě FI provádějí také stavové filtrování provozu pomocí iptables (původně ipchains), detekci skenování sítě a další činnosti. Pro zajímavost: konfigurace packetového filtru má skoro 1700 pravidel pro IPv4 a necelých 900 pravidel pro IPv6. Routery FI provádějí směrování mezi 18 fyzickými i virtuálními (802.1Q) sítěmi, realizovanými nad gigabitovým a desetigigabitovým Ethernetem.
Výpadek 12. dubna dopoledne
V ranních hodinách v 7:56 jsme zaznamenali výpadek vnějšího připojení sítě FI k Internetu. Trochu komplikace při odhalování problému způsobily zprávy od uživatelů o tom, že v rámci sítě FI komunikace funguje a naopak, že problémy se sítí pozorují i v jiných částech Univerzitní sítě. Faktem je, že ve skutečnosti byla od 7:56 síť FI včetně sítě ISu nedostupná z vnějšího světa.
Časový sled událostí, rekonstruovaný zpětně z logů, monitoringu a dalších zdrojů byl následující:
- 7:56
- Primární router má poslední záznamy v logu.
- 7:57
- Sekundární router přebírá směrování, ale jeho logy končí ještě v téže minutě.
- 7:58
- Monitoring sítě hlásí výpadky WiFi accesspointů (ale žádných jiných zařízení ne).
- 8:14
- Monitoring sítě hlásí nedostupnost sekundárního routeru a všech služeb na jiných sítích, než je monitorovací server. Je pravděpodobné, že komunikace v rámci sítě FI fungovala "až" do tohoto okamžiku.
- 8:51
- Po tvrdém resetu bootuje primární router a síť začíná znovu fungovat.
- 9:14
- I sekundární router si nakonec vyžádal tvrdý reset, který jsme po vyřešení urgentnějších problémů, způsobených výpadkem sítě, udělali až nakonec.
Proč spadl téměř zároveň primární i sekundární router? Jako i jindy v minulosti, prokázala se zde užitečnost centrálního logovacího serveru v síti FI. Zasílání logů po síti má totiž tu vlastnost, že často se v případě fatálních problémů poškozenému systému podaří odeslat zprávy z průběhu havárie po síti, i když zápis na disk se už nedokončí.
Na logovacím serveru jsme našli s minutovým rozestupem zprávy o interní chybě jádra jak na primárním, tak na sekundárním routeru. Oba počítače mají různou hardwarovou konfiguraci, ale přesto k chybě došlo v obou případech uvnitř síťové vrstvy. Společnou vlastností obou výpisů zásobníku bylo, že v posloupnosti volaných funkcí se vždy nacházela jedna a tatáž funkce, která se týkala stavové filtrace na aplikační vrstvě.
Poznámka o stavové filtraci: pokud chce jádro systému povolovat nebo zakazovat celá síťová spojení, nelze se u některých protokolů omezovat jen na povolení nebo zakázání jednoho TCP proudu dat. Některé aplikační síťové protokoly, jako například FTP, SIP nebo H.323 komunikují paralelně nebo postupně nad více nezávislými spojeními nebo obecně proudy dat. Pro tyto protokoly musí mít stavový firewall v kernelu speciální podporu, kde se dívá nejen na hlavičky packetů, ale také čte informace zevnitř packetů, a v podstatě parsuje protokol aplikační vrstvy.
Získali jsme tedy dojem, že zřejmě přes naši síť procházel nějaký nestandardní packet jednoho z těchto komplikovanějších aplikačních protokolů, a chybou v modulu pro sledování spojení došlo k pádu jádra nejprve primárního, a o chvíli později i sekundárního směrovače. Podle výpisu zásobníku šlo o kombinaci jednoho z těchto aplikačních protokolů a protokolu IPv6 na třetí vrstvě. K dalšímu výpadku nicméně po restartu obou strojů nedošlo.
NAT Slipstreaming
V poslední době se ve větší míře zpopularizovaly a začaly se objevovat pokusy o tzv. propichování děr ve stavových firewallech pomocí nezabezpečeného webového prohlížeče ve vnitřní síti, který je útočníkem zmanipulován k tomu, aby přistupoval do vnější sítě jakoby protokolem SIP, H.323 nebo podobným.
Tomuto typu útoku se říká NAT Slipstreaming a zajímavé na něm je, že umožňuje útočníkovi zařídit si víceméně přímou komunikaci i se zařízeními ve vnitřní síti oběti, a to i přes použití neveřejných IP adres těchto zařízení a překladu adres (NAT) například na vstupu do domácí sítě. Upozorňujeme tedy i uživatele domácích routerů, že domácí síť s privátními IP adresami ještě neznamená, že by se do ní zvenku nebylo možné dostat.
Tento typ útoku zřejmě stojí za zvýšenou mírou komunikace nad zmíněnými aplikačními protokoly v poslední době, a tedy zvýšenou pravděpodobností, že se projeví případná chyba v parseru těchto protokolů v kernelu Linuxu. Dodejme, že vývojáři předních webových prohlížečů začali v posledních týdnech zakazovat prohlížečům připojit se na porty, obvykle používané těmito službami s komplikovanější stavovou filtrací.
Večerní výpadky
Okolo 18:26 došlo opět k výpadku primárního routeru. Po jeho resetu jsme si již byli jisti, že jde o kombinaci chyby v jádře a plošně probíhajících skenů sítě, směřujících k proniknutí do sítí s překlady adres (NAT). Zkusili jsme tedy nejprve zahazovat na vstupu příslušný aplikační protokol, což ale bohužel nepomohlo. Nicméně sekundární router převzal v pořádku síťový provoz a výpadek připojení byl relativně krátký. V 18:30 už síť zase fungovala.
Jako jednu z dalších příčin jsme odhadovali to, že parsování příslušného aplikačního protokolu se může zavolat ještě dříve, než samotná filtrace, která by tento protokol zahodila. Proto jsme zkusili zakázat příslušné protokoly ještě před vstupem do stavové filtrace, v iptables tabulce raw. Jak se nakonec ukázalo, ani toto nebylo dostatečné, a výsledkem bylo několik dalších kratších výpadků síťové konektivity s převzetím provozu sekundárním a zpět primárním směrovačem. Během posledního výpadku před 20. hodinou jsme nakonec z jádra obou routerů vyřadili podporu pro stavové filtrování některých aplikačních protokolů, v jejichž modulech docházelo k pádu jádra. Toto se ukázalo jako účinné řešení, a i přes trvající zvýšený síťový provoz na těchto protokolech již k pádu systému od té doby nedošlo. Nevýhodou použitého přístupu je, že nyní nefiltrujeme tyto síťové protokoly včetně návazných spojení, a v nestandardnějších konfiguracích nemusí pak fungovat přes hranici sítě FI.

Na výše uvedeném grafu z nástroje Smokeping je vidět zhoršení kvality síťového připojení během večerních výpadků.
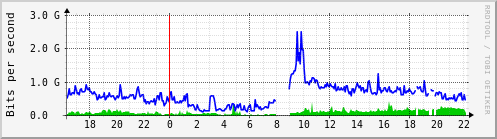
Na grafu síťového provozu fakultního routeru je vidět ranní nedostupnost sítě i kratší večerní výpadky.
Dostupnost naší sítě zvenku lze také ověřit na stránkách projektu RIPE Atlas, kde je vidět dostupnost sondy tohoto projektu, kterou provozujeme v naší síti.
Další opatření
Jako další opatření jsme po dlouhých úvahách na sekundárním routeru aktivovali hardwarový watchdog, což je zařízení na základní desce, které po aktivaci musí od operačního systému periodicky dostávat informace, že operační systém žije. Toto je realizováno speciálním démonem v systému, který zkouší různé aktivity (vytvoření procesu, vytvoření souboru, atd.) a pak zápisem do zařízení /dev/watchdog potvrzuje hardwaru, že systém stále funguje. Pokud watchdog neobdrží toto potvrzení do nastaveného limitu (typicky několik minut), provede tvrdý reset počítače.
Dosud jsme se nasazení hardwarového watchdogu bránili zejména z toho důvodu, že směrování packetů jako činnost běžící uvnitř jádra může na dlouhou dobu blokovat vykonávání uživatelských procesů, a při zvýšeném síťovém provozu by teoreticky mohlo dojít k resetu routeru watchdogem, i když by systém ještě fungoval. Po včerejším incidentu jsme se nicméně rozhodli zapnout watchdog s poměrně konzervativními limity aspoň na jednom ze dvou routerů.
Dalším opatřením je nastavení sysctl parametru jádra kernel.panic = 30, aby se jádro v případě fatální chyby pokusilo po půl minutě restartovat systém. Podle našich zkušeností toto pomůže jen v menším procentu výpadků, protože často je po interní chybě jádra systém v takovém stavu, že není řízeného restartu schopen.
Posledním opatřením pak bude průzkum, jestli se námi pozorovaná chyba projevuje i v novějších upstream jádrech, než je naše distribuční jádro, a případná instalace jiného jádra.
Za výpadky sítě 12. dubna se uživatelům omlouváme a věříme, že jsme učinili jednak opatření směřující k tomu, aby se tento konkrétní problém neopakoval, a jednak systémová opatření směřující k rychlejší nápravě, pokud by se opakoval jiný výpadek podobného typu.
